Scheduling of tasks is one of the most basic, yet most complicated tasks in any production project. The work at hand introduces a real world scheduling problem encountered at exept software AG for which we are introducing a solution approach using a genetic algorithm. The work gives background information on scheduling under resource constraints with deterministic, as well as stochastic processing times. We adopt and benchmark a genetic algorithm described in literature and achieve an improvement of median processing times of 17% as compared to the algorithm which is currently used to solve the problem. The standard deviation of processing times is reduced by 33%.
This repository contains the software created during my Masters thesis. This includes the implementation of the genetic algorithm itself, as well as various tools created during the process. However, the parser which can be used to convert XML files to our data model has been removed since it would expose corporate secrets.
I included an anonymized version of the dataset we used to validate my our Algorithm. The dataset is located in sampleData/anonymized.pickle. It is described in the thesis thoroghly. In this particular version UUIDs and names of tasks, resources etc. have been replaced by randomly generated strings. This does not affect the functionality of the algorithm though.
A lot of this software has been developed in a hurry and the documentation is not always correct / consistent. This also affectsoveral code quality.
Please do not hesitate to contact me if you have any questions.
python setup.py install
I created several tools which helped me during development. The most important ones can be found in the bin folder. All of them can be called with the -h parameter to get a list of possible commands.
To get a basic simulation setup running the following steps are required:
cd bin
./simulator --scheduler PPPolicies --output /tmp/outputfile.pickle ../sampleData/anonymized.pickle
Where
--schedulerspecifies the scheduling policy to be used. All schedulers implemented can be found inschedulers/.--outputspecifies the file the simulation results should be written to- The last parameter specifies the for the scheduling problem which should be solved
A manifestation of the best scheduling priority generated by the simulator can be displayed as Gantt Chart with the visualizer tool:
./visualizer --pdf /tmp/gantt.pdf /tmp/outputfile.pickle
Where --pdf specifies where the resulting pdf plot should be written to.
The resulting diagram should look similar to this:
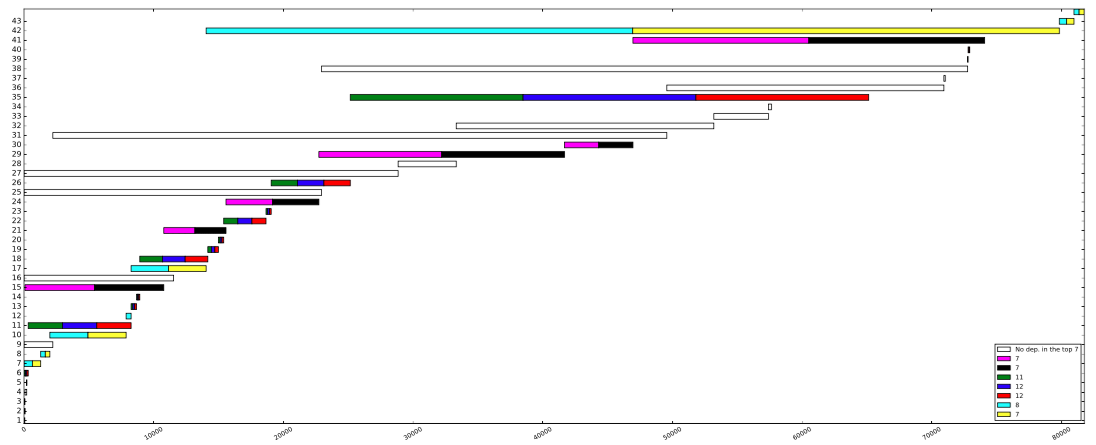
The colors of the taks have the following meaning: The 7 most used resources in the scheduling problem are assigned colors. Every task which requires one ore more of the theses resources is colored respectively. This helps identifying the critical path through the scheduling problem.
If you are interested in how the genetic algorithm performs over time, you can start the simulator command with the --show_gen_log true parameter which plots the fitness of the best and worst individual over time:
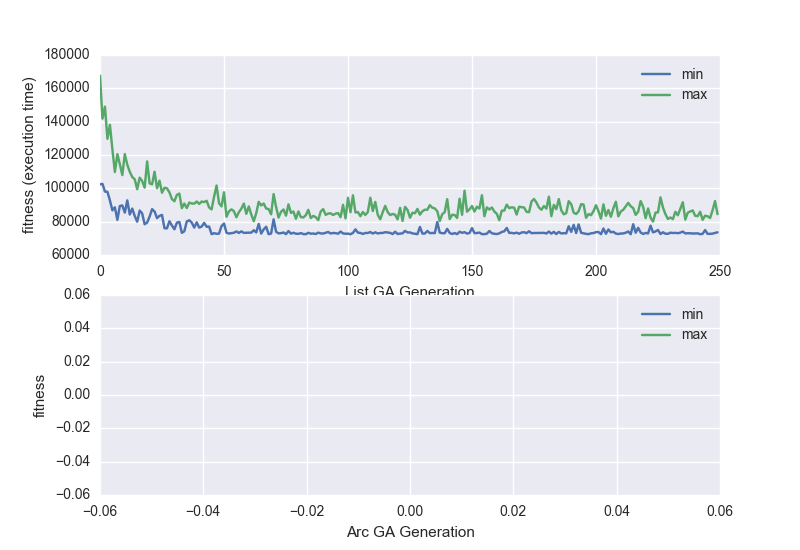
There are also other tools used for optimizing the GA parameters (optimizer) and running simulations on multiple cores (multisim).