mlexperiments_rpart_regression
- Preprocessing
- Experiments
library(mlexperiments)See https://github.com/kapsner/mlexperiments/blob/main/R/learner_rpart.R for implementation details.
library(mlbench)
data("BostonHousing")
dataset <- BostonHousing |>
data.table::as.data.table() |>
na.omit()
feature_cols <- colnames(dataset)[1:13]
target_col <- "medv"
cat_vars <- "chas"seed <- 123
if (isTRUE(as.logical(Sys.getenv("_R_CHECK_LIMIT_CORES_")))) {
# on cran
ncores <- 2L
} else {
ncores <- ifelse(
test = parallel::detectCores() > 4,
yes = 4L,
no = ifelse(
test = parallel::detectCores() < 2L,
yes = 1L,
no = parallel::detectCores()
)
)
}
options("mlexperiments.bayesian.max_init" = 10L)data_split <- splitTools::partition(
y = dataset[, get(target_col)],
p = c(train = 0.7, test = 0.3),
type = "stratified",
seed = seed
)
train_x <- data.matrix(
dataset[data_split$train, .SD, .SDcols = feature_cols]
)
train_y <- dataset[data_split$train, get(target_col)]
test_x <- data.matrix(
dataset[data_split$test, .SD, .SDcols = feature_cols]
)
test_y <- dataset[data_split$test, get(target_col)]fold_list <- splitTools::create_folds(
y = train_y,
k = 3,
type = "stratified",
seed = seed
)# required learner arguments, not optimized
learner_args <- list(method = "anova")
# set arguments for predict function and performance metric,
# required for mlexperiments::MLCrossValidation and
# mlexperiments::MLNestedCV
predict_args <- list(type = "vector")
performance_metric <- metric("mse")
performance_metric_args <- NULL
return_models <- FALSE
# required for grid search and initialization of bayesian optimization
parameter_grid <- expand.grid(
minsplit = seq(2L, 82L, 10L),
cp = seq(0.01, 0.1, 0.01),
maxdepth = seq(2L, 30L, 5L)
)
# reduce to a maximum of 10 rows
if (nrow(parameter_grid) > 10) {
set.seed(123)
sample_rows <- sample(seq_len(nrow(parameter_grid)), 10, FALSE)
parameter_grid <- kdry::mlh_subset(parameter_grid, sample_rows)
}
# required for bayesian optimization
parameter_bounds <- list(
minsplit = c(2L, 100L),
cp = c(0.01, 0.1),
maxdepth = c(2L, 30L)
)
optim_args <- list(
iters.n = ncores,
kappa = 3.5,
acq = "ucb"
)tuner <- mlexperiments::MLTuneParameters$new(
learner = LearnerRpart$new(),
strategy = "grid",
ncores = ncores,
seed = seed
)
tuner$parameter_grid <- parameter_grid
tuner$learner_args <- learner_args
tuner$split_type <- "stratified"
tuner$set_data(
x = train_x,
y = train_y,
cat_vars = cat_vars
)
tuner_results_grid <- tuner$execute(k = 3)
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Parameter settings [=====================================================================================>----------] 9/10 ( 90%)
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Parameter settings [===============================================================================================] 10/10 (100%)
#> Regression: using 'mean squared error' as optimization metric.
head(tuner_results_grid)
#> setting_id metric_optim_mean minsplit cp maxdepth method
#> 1: 1 26.14038 2 0.07 22 anova
#> 2: 2 26.14038 32 0.02 27 anova
#> 3: 3 26.14038 72 0.10 7 anova
#> 4: 4 26.14038 32 0.09 27 anova
#> 5: 5 26.14038 52 0.02 12 anova
#> 6: 6 26.14038 2 0.04 7 anovatuner <- mlexperiments::MLTuneParameters$new(
learner = LearnerRpart$new(),
strategy = "bayesian",
ncores = ncores,
seed = seed
)
tuner$parameter_grid <- parameter_grid
tuner$parameter_bounds <- parameter_bounds
tuner$learner_args <- learner_args
tuner$optim_args <- optim_args
tuner$split_type <- "stratified"
tuner$set_data(
x = train_x,
y = train_y,
cat_vars = cat_vars
)
tuner_results_bayesian <- tuner$execute(k = 3)
#>
#> Registering parallel backend using 4 cores.
head(tuner_results_bayesian)
#> Epoch setting_id minsplit cp maxdepth gpUtility acqOptimum inBounds Elapsed Score metric_optim_mean errorMessage method
#> 1: 0 1 2 0.07 22 NA FALSE TRUE 0.049 -26.14038 26.14038 NA anova
#> 2: 0 2 32 0.02 27 NA FALSE TRUE 0.049 -26.14038 26.14038 NA anova
#> 3: 0 3 72 0.10 7 NA FALSE TRUE 0.049 -26.14038 26.14038 NA anova
#> 4: 0 4 32 0.09 27 NA FALSE TRUE 0.049 -26.14038 26.14038 NA anova
#> 5: 0 5 52 0.02 12 NA FALSE TRUE 0.027 -26.14038 26.14038 NA anova
#> 6: 0 6 2 0.04 7 NA FALSE TRUE 0.027 -26.14038 26.14038 NA anovavalidator <- mlexperiments::MLCrossValidation$new(
learner = LearnerRpart$new(),
fold_list = fold_list,
ncores = ncores,
seed = seed
)
validator$learner_args <- tuner$results$best.setting[-1]
validator$predict_args <- predict_args
validator$performance_metric <- performance_metric
validator$performance_metric_args <- performance_metric_args
validator$return_models <- return_models
validator$set_data(
x = train_x,
y = train_y,
cat_vars = cat_vars
)
validator_results <- validator$execute()
#>
#> CV fold: Fold1
#>
#> CV fold: Fold2
#>
#> CV fold: Fold3
head(validator_results)
#> fold performance minsplit cp maxdepth method
#> 1: Fold1 29.20022 2 0.07 22 anova
#> 2: Fold2 17.76631 2 0.07 22 anova
#> 3: Fold3 31.45460 2 0.07 22 anovavalidator <- mlexperiments::MLNestedCV$new(
learner = LearnerRpart$new(),
strategy = "grid",
fold_list = fold_list,
k_tuning = 3L,
ncores = ncores,
seed = seed
)
validator$parameter_grid <- parameter_grid
validator$learner_args <- learner_args
validator$split_type <- "stratified"
validator$predict_args <- predict_args
validator$performance_metric <- performance_metric
validator$performance_metric_args <- performance_metric_args
validator$return_models <- return_models
validator$set_data(
x = train_x,
y = train_y,
cat_vars = cat_vars
)
validator_results <- validator$execute()
#>
#> CV fold: Fold1
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Parameter settings [=====================================================================================>----------] 9/10 ( 90%)
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Parameter settings [===============================================================================================] 10/10 (100%)
#> Regression: using 'mean squared error' as optimization metric.
#>
#> CV fold: Fold2
#> CV progress [====================================================================>-----------------------------------] 2/3 ( 67%)
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Parameter settings [===============================================================================================] 10/10 (100%)
#> Regression: using 'mean squared error' as optimization metric.
#>
#> CV fold: Fold3
#> CV progress [========================================================================================================] 3/3 (100%)
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Parameter settings [=====================================================================================>----------] 9/10 ( 90%)
#> Regression: using 'mean squared error' as optimization metric.
#>
#> Parameter settings [===============================================================================================] 10/10 (100%)
#> Regression: using 'mean squared error' as optimization metric.
head(validator_results)
#> fold performance minsplit cp maxdepth method
#> 1: Fold1 29.20022 2 0.07 22 anova
#> 2: Fold2 17.76631 2 0.07 22 anova
#> 3: Fold3 31.45460 2 0.07 22 anovavalidator <- mlexperiments::MLNestedCV$new(
learner = LearnerRpart$new(),
strategy = "bayesian",
fold_list = fold_list,
k_tuning = 3L,
ncores = ncores,
seed = seed
)
validator$parameter_grid <- parameter_grid
validator$learner_args <- learner_args
validator$split_type <- "stratified"
validator$parameter_bounds <- parameter_bounds
validator$optim_args <- optim_args
validator$predict_args <- predict_args
validator$performance_metric <- performance_metric
validator$performance_metric_args <- performance_metric_args
validator$return_models <- TRUE
validator$set_data(
x = train_x,
y = train_y,
cat_vars = cat_vars
)
validator_results <- validator$execute()
#>
#> CV fold: Fold1
#>
#> Registering parallel backend using 4 cores.
#>
#> CV fold: Fold2
#> CV progress [====================================================================>-----------------------------------] 2/3 ( 67%)
#>
#> Registering parallel backend using 4 cores.
#>
#> CV fold: Fold3
#> CV progress [========================================================================================================] 3/3 (100%)
#>
#> Registering parallel backend using 4 cores.
head(validator_results)
#> fold performance minsplit cp maxdepth method
#> 1: Fold1 29.20022 2 0.07 22 anova
#> 2: Fold2 17.76631 2 0.07 22 anova
#> 3: Fold3 31.45460 2 0.07 22 anovaSee https://github.com/kapsner/mlexperiments/blob/main/R/learner_lm.R for implementation details.
validator_lm <- mlexperiments::MLCrossValidation$new(
learner = LearnerLm$new(),
fold_list = fold_list,
ncores = ncores,
seed = seed
)
validator_lm$predict_args <- list(type = "response")
validator_lm$performance_metric <- performance_metric
validator_lm$performance_metric_args <- performance_metric_args
validator_lm$return_models <- TRUE
validator_lm$set_data(
x = train_x,
y = train_y,
cat_vars = cat_vars
)
validator_lm_results <- validator_lm$execute()
#>
#> CV fold: Fold1
#> Parameter 'ncores' is ignored for learner 'LearnerLm'.
#>
#> CV fold: Fold2
#> Parameter 'ncores' is ignored for learner 'LearnerLm'.
#>
#> CV fold: Fold3
#> Parameter 'ncores' is ignored for learner 'LearnerLm'.
head(validator_lm_results)
#> fold performance
#> 1: Fold1 35.49058
#> 2: Fold2 22.04977
#> 3: Fold3 21.39721mlexperiments::validate_fold_equality(
experiments = list(validator, validator_lm)
)
#>
#> Testing for identical folds in 1 and 2.
#>
#> Testing for identical folds in 2 and 1.preds_rpart <- mlexperiments::predictions(
object = validator,
newdata = test_x
)
preds_lm <- mlexperiments::predictions(
object = validator_lm,
newdata = test_x
)perf_rpart <- mlexperiments::performance(
object = validator,
prediction_results = preds_rpart,
y_ground_truth = test_y,
type = "regression"
)
perf_lm <- mlexperiments::performance(
object = validator_lm,
prediction_results = preds_lm,
y_ground_truth = test_y,
type = "regression"
)# combine results for plotting
final_results <- rbind(
cbind(algorithm = "rpart", perf_rpart),
cbind(algorithm = "lm", perf_lm)
)p <- ggpubr::ggdotchart(
data = final_results,
x = "algorithm",
y = "mse",
color = "model",
rotate = TRUE
)
p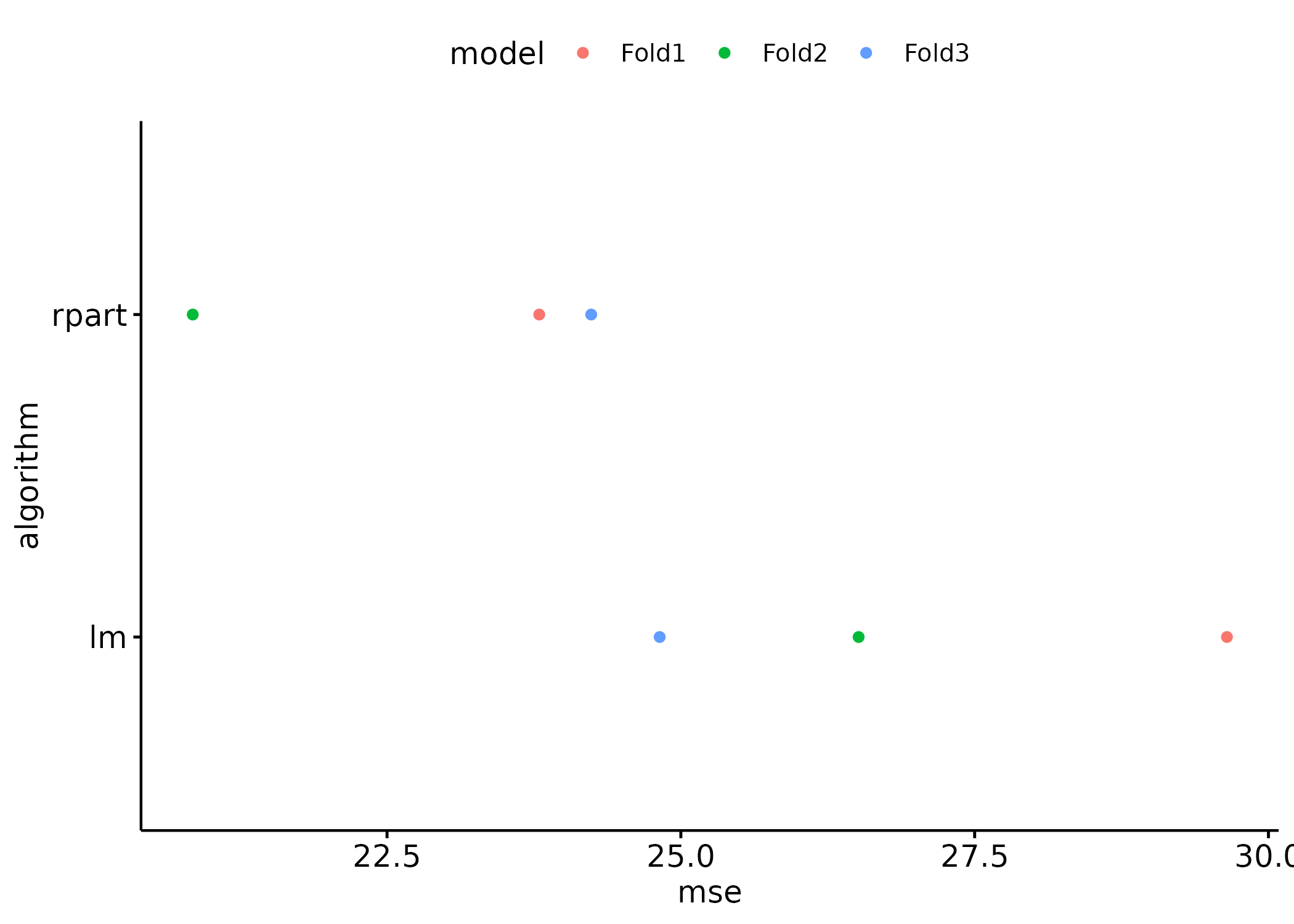 Model Comparison
Model Comparison