
Beanbun 是一个简单可扩展的爬虫框架,支持分布式,支持守护进程模式与普通模式,守护进程模式基于 Workerman,下载器基于 Guzzle。
https://github.com/kiddyuchina/Beanbun/blob/master/docs/chs/README.md
推荐一下最近发现的一个很好用的全球代理:SmartProxy
专业海外http代理商,有1亿真实住宅IP资源,覆盖全球,高匿稳定提供100%原生住宅IP,支持社交账户、电商平台、网络数据收集等服务。
匿名性很好,伪装度很高,IP限制问题轻松解决。
本人测试用过之后感觉很不错。
现春季价格优惠,动态住宅代理只要65折!

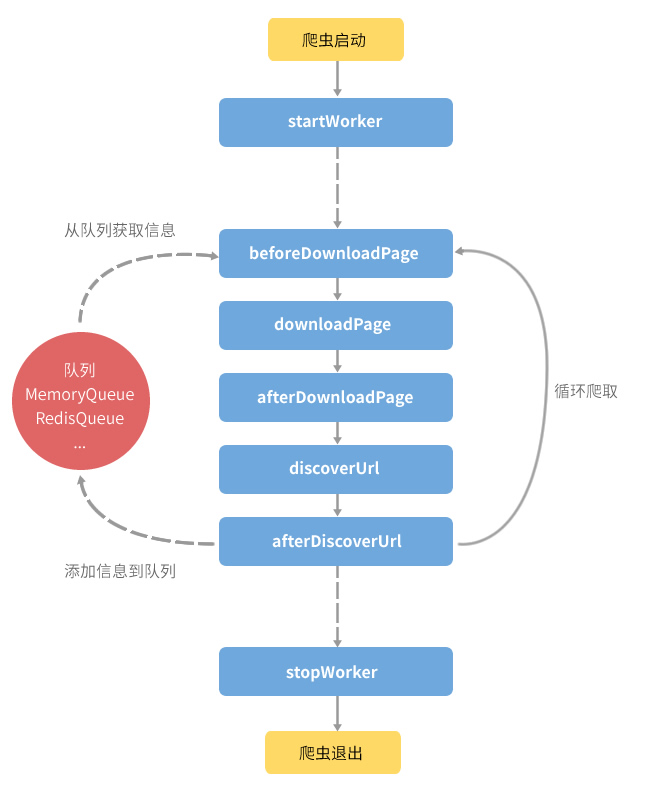
- 支持守护进程与普通两种模式(守护进程模式只支持 Linux 服务器)
- 默认使用 guzzle 进行爬取
- 支持分布式
- 支持内存、Redis 等多种队列方式
- 支持自定义URI过滤
- 支持广度优先和深度优先两种爬取方式
- 遵循 PSR-4 标准
- 爬取网页分为多步,每步均支持自定义动作(如添加代理、修改 user-agent 等)
- 灵活的扩展机制,可方便的为框架制作插件:自定义队列、自定义爬取方式...
Beanbun 可以通过 composer 进行安装。
$ composer require kiddyu/beanbun
创建一个文件 start.php,包含以下内容
<?php
use Beanbun\Beanbun;
$beanbun = new Beanbun;
$beanbun->seed = [
'http://www.950d.com/',
'http://www.950d.com/list-1.html',
'http://www.950d.com/list-2.html',
];
$beanbun->afterDownloadPage = function($beanbun) {
file_put_contents(__DIR__ . '/' . md5($beanbun->url), $beanbun->page);
};
$beanbun->start();在命令行中执行
$ php start.php
接下来就可以看到抓取的日志了。
- beanbun-parser 数据抽取插件 https://github.com/kiddyuchina/beanbun-parser
更多详细内容,请查看 文档