RFC-0022: Proposal for adding new restart policy to torch.distributed… #34
There are no files selected for viewing
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,327 @@ | ||
| # torchelastic soft restarts - Enabling training without restarting the world | ||
|
|
||
| This RFC proposes a new restart policy to the `torch.distributed.elastic` package. | ||
| We use `torch.distributed.run`, torchelastic and TE interchangeably in this document. | ||
|
|
||
|
|
||
| ## Background | ||
|
|
||
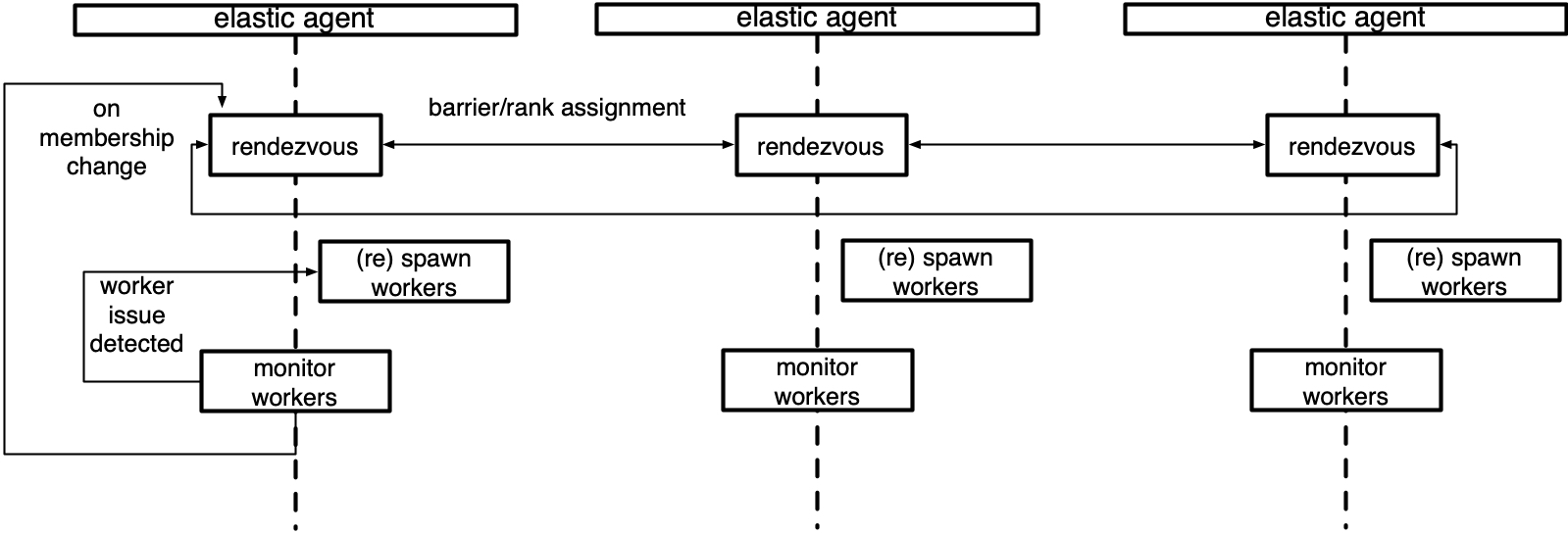
| Distributed training with pytorch usually consists of the following workflow (see diagram below): | ||
|
|
||
| 1. Users use torch.distributed.run to start jobs on a single node. | ||
| 2. They use the same command on N different machines. | ||
| 3. The torch.distributed.run would start a TE agent that acts as a process manager. It starts and manages worker processes. | ||
| 4. Worker processes use pytorch distributed to initialize process groups and execute training. | ||
|
|
||
|  | ||
|
|
||
| The current behavior for `torch.distributed` process groups is that it induces a failure on all workers in the job if | ||
| any worker fails. | ||
| In the case of `backend=nccl`, any worker failure causes other workers to get stuck in the CUDA kernel. | ||
| This is because nccl ops use spin locks on the device for optimization purposes. | ||
| To remedy this, there is a watchdog thread that raises a `TimeoutError` if CUDA ops get stuck. | ||
|
|
||
| Upon detecting a worker failure (PID no longer exists), the TE agents on each node will terminate | ||
| all surviving workers and re-spawn the workers in compliance to the user set min and max number of workers. | ||
| We call this global restart behavior as a hard restart. | ||
|
|
||
| ## Motivation | ||
|
|
||
| While hard restarts make it possible for existing training scripts to be invoked with TE for fault tolerance, | ||
| it is not optimal for training scripts that (not an exhaustive nor mutually exclusive list): | ||
|
|
||
| 1. have expensive initialization logic | ||
| 2. those that cannot checkpoint often (for various reasons) | ||
| 3. already internally withstand worker failures (e.g. parameter servers, readers) | ||
| 4. can run to completion with surviving workers without replacement of failed workers | ||
|
|
||
| For these types of applications a soft restart policy is desired where on worker | ||
| failure surviving workers are not hard terminated and restarted by TE but rather | ||
| notified that a change-in-peers event has occurred with information | ||
| about the new RANK, WORLD_SIZE, MASTER_ADDR, and MASTER_PORT. The survivors use this information | ||
| to reinitialize in-process and continue making progress. | ||
|
|
||
| <em>Note that even in the presence of soft restarts, | ||
|
There was a problem hiding this comment. Curious what's the most used backend externally, is it nccl? |
||
| DDP scripts that use torch.distributed process groups | ||
| with the nccl backend won’t be able to run to completion with partial failures. | ||
| This is because currently, a worker failure induces | ||
| an uncatchable failure (SIGABRT rather than an Exception) on other workers, | ||
| leaving no surviving workers behind. | ||
| We acknowledge this as a caveat and will address this in future releases of PyTorch. | ||
| The rest of this document assumes that induced exceptions on surviving workers are catch-able.</em> | ||
|
|
||
| ## Description | ||
|
|
||
| We propose adding a soft restart policy to TE. Users can launch their scripts with soft restarts | ||
| enabled by passing the `--restart_policy=soft` parameter to `torch.distributed.run` as: | ||
|
|
||
| ``` | ||
| python -m torch.distributed.run \ | ||
| --restart_policy soft \ | ||
| --nnodes 2 \ | ||
| --nproc_per_node 4 \ | ||
| main.py | ||
| ``` | ||
|
|
||
| The command above, when run on two separate nodes, launches 2x4 copies of `main.py` | ||
| with a soft restart policy. If a worker fails on node 1, then its local peers are force | ||
| terminated - but not restarted - and the workers on node 2 are notified on this event. | ||
| Since the new rank and world size information needs to be propagated to the | ||
| surviving workers on node 2, the application code needs to be changed to use the | ||
| included runtime API to receive this information. For instance for simple trainers, | ||
| the application’s code would look like the following pseudo-code (runtime API underlined): | ||
|
|
||
| ```buildoutcfg | ||
| while local_attempts < maximum_attempts: | ||
| try: | ||
| dist.init_process_group( | ||
| backend="nccl", | ||
| **worker_info.get_pg_parameters(), # rank, world_size, master info | ||
| ) | ||
| for epoch in range(state.epoch, state.total_epochs): | ||
| for batch in dataloader: | ||
| do_train(batch, state.model) # implemented by user | ||
| state.epoch +=1 | ||
|
|
||
| if dist.get_rank() == 0 | ||
| maybe_save_checkpoint(state) | ||
| except Exception e: | ||
| log_failure(state, e) | ||
| dist.destroy_process_group() | ||
| worker_info = torch.distributed.elastic.get_worker_info() | ||
| reset(worker_info) # implemented by user | ||
|
There was a problem hiding this comment. Does the user need to implement this? Or can we provide a reference implementation? For example, we know we need to run |
||
|
|
||
|
|
||
| ``` | ||
|
|
||
| This document describes addition of a soft restart policy that behaves according to the following table: | ||
|
|
||
| | Scale up event | Scale down event | Worker failure | | ||
| |----------|:-------------:|------:| | ||
| | Hard Restart Policy | Terminate workers, perform re-rendezvous | Terminate workers, perform re-rendezvous | Terminate workers, perform re-rendezvous | | ||
| | Soft restart Policy | Broadcast PAUSE, start re-rendezvous, Broadcast WORK | Broadcast PAUSE, start re-rendezvous, Broadcast WORK | Terminate local workers, decrease max_restarts, proceed with scale-down event | | ||
|
There was a problem hiding this comment. nit: I wonder if there's a more descriptive name we could use. Hard restart makes sense. Hard restart: Restart TE, Restart failed node So maybe something like restartnode, donotrestartnode and later we'd add something like updatenode (for things like updating batch sizes) |
||
|
|
||
|
|
||
| ## Implementation Details | ||
|
|
||
| This section describes the internal workings of the proposed soft restarts presented | ||
| in the Description section. | ||
|
|
||
| ### Torchelastic API changes | ||
|
|
||
| TE can be executed both programmatically and via command line. | ||
| In order to use a new policy via cmd, one should use a new `--restart_policy` flag, e.g.: | ||
|
|
||
| ``` | ||
| python -m torch.distributed.run \ | ||
| --restart_policy soft \ | ||
| --nnodes 2 \ | ||
| --nproc_per_node 4 \ | ||
| main.py | ||
| ``` | ||
|
|
||
| If the flag is omitted, the default policy will be executed. | ||
|
|
||
| `torch.distributed.launcher.api.LaunchConfig` will get a new parameter: RestartPolicy | ||
|
|
||
| ``` | ||
| # Note: The policy name most likely will be changed | ||
| class RestartPolicy: | ||
| HARD | ||
| SOFT | ||
|
|
||
| class LaunchConfig: | ||
| ... | ||
| restart_policy: RestartPolicy | ||
|
|
||
| # launching an agent with soft-restart policy | ||
| from torch.distributed.launcher import launch_agent, RestartPolicy, LaunchConfig | ||
|
|
||
| results = launch_agent(config=LaunchConfig(..., restart_policy=RestartPolicy.SOFT, ...) | ||
|
|
||
| ``` | ||
|
|
||
| ### Worker(trainer) API changes | ||
|
|
||
| Trainer logic should be modified as well to use the soft restart policy. | ||
| When TE starts a group of processes, it populates their env. variables with necessary | ||
| information to set up the process group: WORLD_SIZE, RANK, MASTER_ADDR, MASTER_PORT. | ||
| There is no need for workers to communicate back to TE agent process. | ||
| This functionality needs to be changed, since env variables cannot be used anymore. | ||
|
|
||
| The following API will be introduced: | ||
|
|
||
| ```python | ||
|
|
||
| # module: torch.distributed.elastic.runtime | ||
|
|
||
| @datalcass | ||
| class WorkerEvent: | ||
| # timestamp when the event occurred | ||
| timestamp: int | ||
| worker_info: WorkerInfo | ||
| worker_state: WorkerState | ||
| change_event: Optional[WorldChangeEvent] | ||
|
|
||
| class WorldChangeEvent(Enum): | ||
| """ | ||
| Enum representing the reason of the event. This information will be devided on worker | ||
| process. | ||
| """ | ||
| SCALE_UP, | ||
| SCALE_DOWN | ||
|
|
||
| class WorkerState(Enum): | ||
| """ | ||
| Enum representing the state of the worker that is advertised | ||
| by the agent. It is up to the worker process to treat the | ||
| state according to the its logic. | ||
| """ | ||
| HEALTHY = "HEALTHY" | ||
| PAUSED = "PAUSED" | ||
|
|
||
| @dataclass | ||
| class WorkerInfo: | ||
| # worker rank across a single node. | ||
| local_rank: int | ||
| # worker rank across a single role | ||
| role_rank: int | ||
|
|
||
| # worker global rank across all workers and roles | ||
| rank: int | ||
| # number of workers managed by the TE agent | ||
| local_world_size: int | ||
| # number of workers participating in the current role | ||
| role_world_size: int | ||
| # global number of workers | ||
| world_size: int | ||
|
|
||
| # new master address and port that can be used to initiate a new process group | ||
| master_addr: str | ||
| master_port: int | ||
|
|
||
| def get_worker_event() -> WorkerEvent: | ||
| """ | ||
| Returns the last event that is observed on the worker process. | ||
| If there is no events observed, returns the latest recorded event. | ||
| TE agent always sends initial event to the worker process, as a result | ||
| worker process can use this method immediately. | ||
| """ | ||
| pass | ||
|
|
||
| def get_worker_info() -> WorkerInfo: | ||
| """ | ||
| Reads the last event that is observed on the worker process. | ||
| Convenience method, see `get_worker_event` for more info. | ||
| """ | ||
| pass | ||
|
|
||
| ``` | ||
|
|
||
| ### Soft Restart Policy Description | ||
|
|
||
| To better understand how soft-restarts work, we split the soft restart behavior description | ||
| into the following parts: | ||
| 1. scale up event | ||
| 2. scale down event | ||
| 3. worker failure event. | ||
|
|
||
| #### Scale down event | ||
|
|
||
| Scale down event occurs when one or more TE agents become unresponsive. | ||
| This may happen due to network issues, nodes finishing unexpectedly or agents getting terminated. The | ||
| surviving agents will follow the next protocol: | ||
|
|
||
| 1. The surviving TE agents will detect that scale-down event occurred and execute a soft restart policy. | ||
| 2. TE agents will broadcast a PAUSE message to the local workers and will start a new rendezvous round. | ||
| 3. Existing TE agents will wait for new TE agents to join rendezvous. | ||
| 4. If the total number of TE agents at the end of the wait period is between configured `min` and `max`, all TE agents will conclude that the rendezvous round is successful. | ||
|
There was a problem hiding this comment. What's the dataclass look like for a policy it sounds like we have @dataclass
class Policy:
# Min nodes
min_nodes : int
# Max nodes
max_nodes : int
# Waiting time in ms
wait_period : int
# What else?Also question about the |
||
| 1. If the total number of TE agents is not between `min` and `max`, TE agents will start the rendezvous failure procedure. They will terminate existing workers and exit with rendezvous errors. | ||
| 5. TE agents will update their worker infos and propagate the events to the worker processes. | ||
| 6. Worker processes will read events and restart train loop. | ||
|
|
||
|
|
||
| #### Scale up event | ||
| The scale up event occurs when TE detects a new agent trying to join the cluster: | ||
|
|
||
| 1. TE agents will stop the current rendezvous round without terminating workers. | ||
| 2. The rendezvous algorithm will follow the scale down event. | ||
| 3. It is important to mention that workers should periodically check the current status | ||
| of the world and re-initialize if they detect a membership change event. | ||
|
|
||
| #### Worker failures | ||
|
|
||
| The worker failure is a special case of failure, where the worker process deliberately | ||
| fails with an Exception or Signal. The correct procedure may depend on the application type. | ||
| There are several possibilities: | ||
|
|
||
| 1. `soft-no-replace` Terminate the existing workers on the local TE agent and decrease max_restarts. | ||
| When a single worker fails, the corresponding TE will terminate all its local workers. | ||
| If the amount of max_restarts is greater than 0, the TE agent will start a new rendezvous round. | ||
| This would be similar to a scale up event. | ||
|
|
||
| 2. `soft-replace` Restart the surviving worker. In this case we need to maintain the max_restarts parameter per | ||
| worker process, which makes things very complex. The current use-cases do not need this level of granularity. | ||
|
|
||
| 3. Record the failure, and wait while other workers finish. This is a true-soft restart use-case. | ||
| The issue is that it violates the current TE architecture: TE was designed to work with homogeneous | ||
| group nodes. By leaving existing workers alive we create a heterogeneous group, which will make | ||
| things hard to debug for the final user. | ||
|
|
||
|
|
||
| For this RFC we will consider #1 option: `soft-no-replace`. In future releases we will add the additional `soft-replace` | ||
| restart policy. | ||
|
|
||
| ### Message passing protocol | ||
|
|
||
| It is assumed that there will be infrequent calls between the worker and the TE agent. | ||
| The size of the message between two processes will not be greater than 1 MiB. | ||
| This means that the requirements are pretty relaxed and almost any type of communication | ||
| pattern can suit the use-case. The message protocol consists of a message channel, | ||
| serialization formats and message objects. The message objects may be the same as in the API section above. | ||
|
|
||
| #### Serialization formats | ||
| Almost any format can suit the use-case, but the favorable candidate is json. | ||
|
|
||
| #### Message channel | ||
| Message channel serves as a communication layer between agent and worker. | ||
| It will be designed following the consumer-producer pattern, | ||
| where an agent is a producer and workers are the consumers of the events. | ||
|
|
||
| The communication layer may then be extended to allow workers to send messages to the agent. | ||
| The communication will be pull based. TE Agents will send events to the message channel if they observed | ||
| the world change event. Worker processes will consume the events in order and apply them to get the | ||
| latest state of the world. | ||
|
|
||
| There are several alternatives that can be used for communication backend: | ||
|
|
||
| 1. multiprocessing.Queue | ||
| 1. This is in fact how torchelastic expiration timers are implemented (see [docs](https://pytorch.org/docs/stable/elastic/timer.html)). | ||
| 2. Downside is that the trainer has to be launched with multiprocessing.spawn() and cannot be launched with subprocess.Popen(). | ||
| 2. torch.rpc | ||
| 1. Robust option, we can use torch.rpc under the hood to send and receive messages. | ||
| 2. We'd get bi-directional channel for free since rpc works for agent → trainer as well as trainer → agent. | ||
| 3. The downside is that it might be an overkill for what we want to do since torch.rpc was designed to actually send over tensors P2P | ||
| 4. Tt might be tricky to overlap trainer process_groups and agent<>trainer rpc groups | ||
| 3. File based | ||
| 1. Robust choice for 90% of the use-cases. Idea is to create a directory per (agent, worker) channel and drop files with the serialized Msg on sends. A file watcher is used on the receiver-side. One can use the dir and file name + structure to organize the channel in a logical way. | ||
|
There was a problem hiding this comment. Are you leaning on picking this option? |
||
| 2. Posix filesystem semantics basically guarantee strong consistency - we do have to be careful of non-posix mounts (e.g. S3 FUSE). In most cases we can circumvent this by using a guaranteed on device volume like /tmp since we would only write triple digit kBs at most. | ||
|
|
||
|
|
||
| #### RestartPolicy interface | ||
|
|
||
| The core torchelastic agent logic will be modified. | ||
| TE core logic consists of the monitor loop that acts as a state machine. | ||
| The new `RestartPolicyStrategy` interface will be introduced. | ||
| The interface will aggregate a common logic for different policy algorithms. | ||
| The current hard restart algorithm will be moved to the `HardRestartPolicyStrategy` class. | ||
| The new `SoftRestartPolicyStrategy` will be implemented that will incorporate soft-restarts behavior. | ||
|
|
||
| The TE monitoring loop will be changed to detect both scale down and scale up events. | ||
| It currently detects scale-up events. This functionality would require careful testing, | ||
| making sure that rendezvous does not happen twice on a scale-down event: e.g. when a node | ||
| goes missing and node re-appears. | ||
|
|
||
|
|
||
| ## Future Work: Modifying torch.distributed process groups | ||
|
|
||
| 1. The follow up step will be to modify `torch.distributed`, process groups, specifically nccl` backend, to make sure that they work with the soft restart policy. | ||
| 2. We will also implement additional variations of soft restart policy, as described in the `Worker failures` section. | ||
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Also worth mentioning that soft restarts means you're spending less time restarting things especially as failures become more common with larger setups