[Core] InfiniBand and RDMA support for Ray object store #30094
Comments
|
Hey awesome! I believe the you can perhaps start at the object store: https://github.com/ray-project/ray/tree/master/src/ray/object_manager cc @jjyao |
|
Hi @hellofinch thanks for bringing this up ! Yes it is one of the key missing piece in Ray to better support HPC workloads and current object store only uses ethernet for object transfer that is expected to be significantly slower. Do you have a particular workload / use case in mind that drives the need for IB support ? We have been hearing similar asks from the community but haven't reached critical mass of prioritization yet. |
|
cc @cadedaniel |
|
@hellofinch Thanks for willing to contribute! I can talk about the high level code that does the Ray object transfer: On the data receiver side: we have pull_manager.cc that sends the object pull request to the sender side to initiate the data transfer. On the data sender side, we have HandlePull which is the entry point for handling the pull request from the data receiver. Then if you follow the code, data sender will then push the data to the receiver via a push grpc. Hopefully this helps you to get started with the code base. Feel free to ask if you have any questions! |
|
Thanks for all your responses! @jjyao I try to start with the code base as you mentioned. I used to follow the program running and I tried to debug the whole ray code. I started the ray head and ray worker. I get many processes that have a relationship with ray such |
|
@hellofinch what function you are referring to. For the data transfer, it happens inside raylet. If it helps, I can also do a quick video call to introduce the related code you are interested in. |
|
It is exactly what I need! I can work on this together, if needed. |
|
What's the state of this issue? Can we consider integrating brpc to support RDMA? |
|
We have the same need for our HPC workloads. In addition to RDMA into CPU memory, it would also be good to support CPU-GPU RDMA and GPU-GPU RDMA (https://developer.nvidia.com/gpudirect). Ideally, tensors (e.g., Torch tensors) whose data is on the GPU would be automatically and transparently transferred by Ray using GPUdirect RDMA whenever possible. For distributed gradient descent (DDP) in deep learning, the frameworks already take care of this with internal communications primitives. The main immediate use case for us is high performance data transfer from storage to GPUs. Each GPU easily consumes gigabytes per second in input data, and on machines with 16 GPUs, GPUdirect RDMA is really the only way of handling those data rates (such machines have separate networking cards for each pair of GPUs capable of transferring directly into GPU memory without going through the main PCI bus). So, it would be great to see support for RDMA transfer for tensors, and for such transfers to go either to/from CPU memory and/or to/from GPU memory. |
|
We would love to explore this path. However, we do not have much expertise
in this domain, would it be possible to explore a collaboration here?
…On Thu, Mar 2, 2023 at 2:34 PM Tom ***@***.***> wrote:
We have the same need for our HPC workloads.
In addition to RDMA into CPU memory, it would also be good to support
CPU-GPU RDMA and GPU-GPU RDMA (https://developer.nvidia.com/gpudirect).
Ideally, tensors (e.g., Torch tensors) whose data is on the GPU would be
automatically and transparently transferred by Ray using GPUdirect RDMA
whenever possible.
For distributed gradient descent (DDP) in deep learning, the frameworks
already take care of this with internal communications primitives.
The main immediate use case for us is high performance data transfer from
storage to GPUs. Each GPU easily consumes gigabytes per second in input
data, and on machines with 16 GPUs, GPUdirect RDMA is really the only way
of handling those data rates (such machines have separate networking cards
for each pair of GPUs capable of transferring directly into GPU memory
without going through the main PCI bus).
So, it would be great to see support for RDMA transfer for tensors, and
for such transfers to go either to/from CPU memory and/or to/from GPU
memory.
—
Reply to this email directly, view it on GitHub
<#30094 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/ABCRZZNVIML7BSH4YISTYVDW2EN5NANCNFSM6AAAAAAR2HHANI>
.
You are receiving this because you commented.Message ID:
***@***.***>
|
|
Thanks for your inputs @tmbdev, this makes a lot of sense and we're seeing a few more use cases from users. I have only worked on and used GPU-GPU RDMA (ray collective using NCCL) with a few questions regarding CPU-GPU RDMA:
Happy to learn more and collaborate on this as after a number of pushes we seem to be back on track to have p2p/collectives again :) |
|
@jiaodong Thanks for the feedback. RoCE (RDMA over Ethernet) is basically Infiniband encapsulated in UDP. I believe the APIs are the same for RoCE and Infiniband. I think as far as Ray is concerned, it just needs support for the RDMA mechanisms. You can probably do all the necessary development and testing with Soft-RoCE on both ends. https://enterprise-support.nvidia.com/s/article/howto-configure-soft-roce Whether any particular hardware and networking configuration actually gives you high performance then depends a great deal on the details of the configuration. The p4d.24xlarge seems to have Infiniband cards for the GPUs, but presumably the commodity CPU workers are on Ethernet. You can probably make that configuration work, but whether it is efficient depends on what hardware is doing the RoCE to Infiniband translation. But if there are hardware performance bottlenecks, they are going to be fixed one way or another pretty soon. They shouldn't affect the design of any Ray RDMA primitives. I think another question is whether any such support in Ray can be based on NCCL or needs other libraries. Right now, NCCL in Ray does not support CPU-to-GPU communications, but there are plugins that may enable that. UCX or UCX-Py may also be options. https://developer.nvidia.com/blog/high-performance-python-communication-with-ucx-py/ |
I'm one of the UCX-Py developers, and I see Ray is mostly built on C++, so it may not be a great fit there as UCX-Py mainly provides Python bindings to UCX and a Python asyncio interface. However, the timing seems perfect as we are finalizing the work on what is currently named UCXX, which is a complete rewrite of UCX-Py by means of a C++ backend. UCX does not support disk access via GPUDirect Storage, and neither does NCCL, for that KvikIO may be used instead. Also NCCL is targeted more at collective communication patterns, if that is something that may be leveraged in Ray, NCCL may be a better alternative than UCX, but I do not have benchmarks to guarantee that you will indeed see better performance. The UCX community has also been working a on the Unified Collective Communication (UCC), but that is not currently supported by UCXX and I'm not much involved and do not know how it compares to NCCL currently. If you decide to experiment with UCXX in Ray, please feel free to ping me and I'll try to assist. |
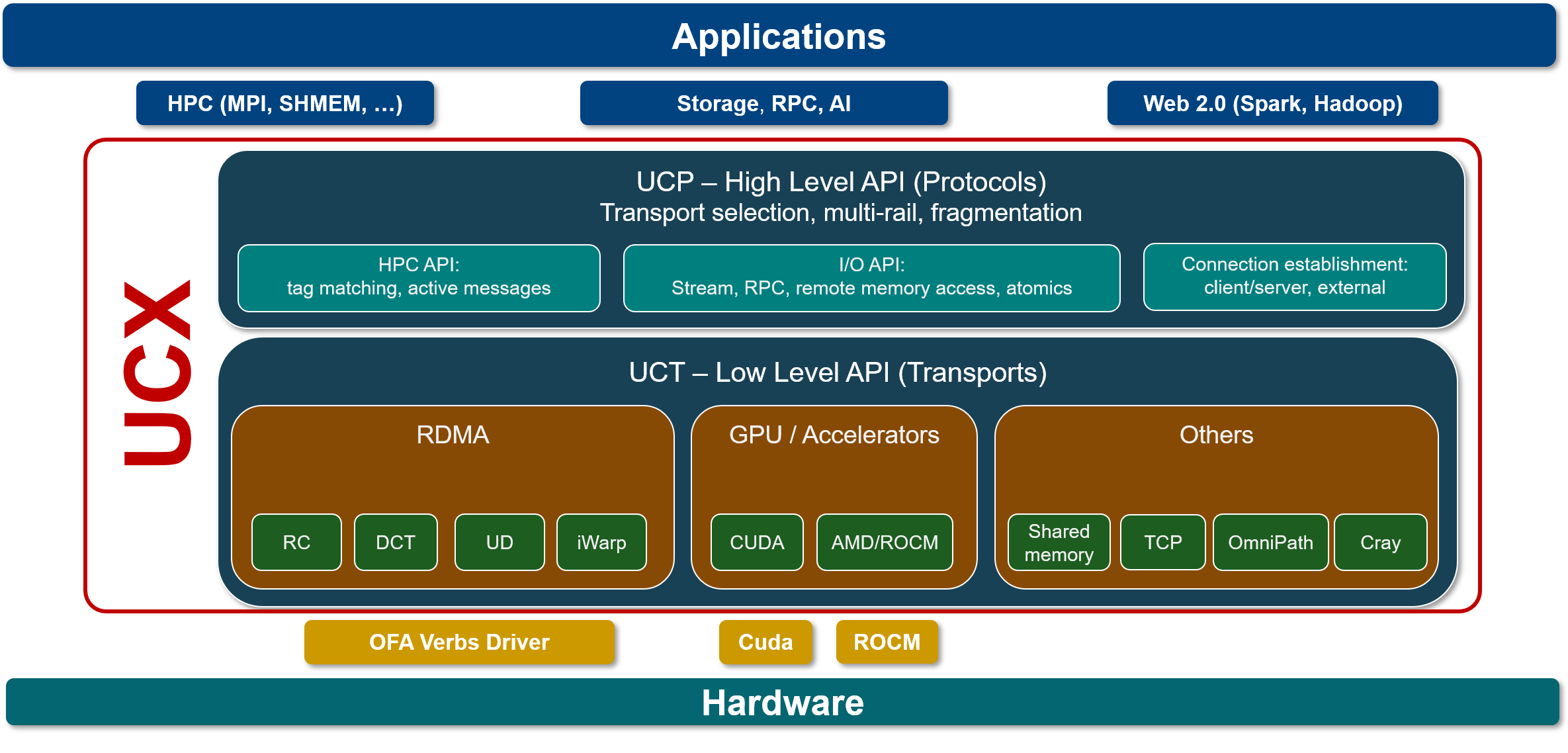{kind=link}
|
Thanks a lot for your inputs @pentschev ! I am on paternity leave right now and likely won't be very active in the next a few months .. cc: @scv119 do you mind making a pass on this and suggest what's the best action we take in the meantime ? It looks very suitable to what Ray Core are looking into recently as well as our recent sync with Ant. |
|
@SongGuyang, I consider that. I try to make gRPC run on RDMA. I meet some bugs when I test stream RPC. Ray can run on RDMA in the least modified if the bugs are easy to fix. If the bugs are challenging to fix, I will try to use brpc. @pentschev, hello Is it possible to make UCX support gRPC which ray is based on? In this way, I think I can minimize the modifications to Ray's source code. It can make Ray more flexible. As for data transfer, can I use UCX to transfer the object between nodes? |
|
Hi @hellofinch , I guess it would be theoretically possible to support UCX in gRPC. I went through some of the issues on gRPC that may be related and it appears there was little activity, for example your question remains unanswered in their discussion list. With that said, I can’t comment on whether there is an open interest from the gRPC community to introduce UCX support in there or RDMA support in general, it may require some more active engagement from Ray together with the gRPC community to get the ball rolling, but that is my impression only and there may be other ongoing discussions I am not aware of. I do not have experience with gRPC and may be biased, but from a very high-level overview, it appears to me that the complexity to implement UCX as a gRPC backend may be similar to implementing UCX as an alternate communication backend in Ray (meaning the user would have to choose gRPC or UCX). It is thus possible that it will be faster to get UCX implemented as an alternate communication backend in Ray, clearly there’s open interest to have RDMA supported here. After consulting some people internally who do have experience with gRPC it was suggested that a hybrid approach could work well for Ray, rather than what I wrote in the paragraph above. The idea would be to keep control messages within gRPC and use UCX where desired, such as places where RDMA could be beneficial. It seems that the main benefit from having gRPC is to use Protobuf in that scenario, where you can ensure a contract between client and server. In UCXX I implemented a “multi-buffer transfer”, that can send(or receive) multiple frames with a single API call, internally it will send(receive) a header and follow to send(receive) the actual frames, without any boilerplate code from the user, so that could be an alternative should you choose to have a fully UCX-backed implementation. All the above being said, I’m open to help you in the effort to making UCX support in Ray a reality, either directly or through gRPC, I can definitely help answering questions and reviewing code, although I cannot commit at this time to write much of the code myself. If you wish to engage with the gRPC community, feel free to include me in the discussions to help answering any questions related to UCX too. |
|
Putting a new backend under gRPC is not the right way to go. Neither gRPC nor protobuf was designed for efficient tensor transfers via RDMA (or any high-performance data transfers). I think a better approach is to use gRPC to set up the transfers but carry out the actual transfers differently. For example, for efficient transfers of tensors, you want zero-copy direct memory-aligned transfers from a source tensor location to a target tensor location. |
|
Thanks for your responses. @pentschev @tmbdev Thanks for your advice. And I get confused. In the current version of Ray, Dose tensors transporting use gPRC? Is it because gRPC can be used uniformly?
|
|
@hellofinch @pentschev @tmbdev thanks for your interest to Ray and contributing to the discussion. Frankly speaking I'm not an expert on RDMA so I might need your help. Currently I'm evaluating if we should use UCX, or MPI style (gloo/nccl) API to improve Ray's object transfer (cpu<->cpu, cpu<->gpu, gpu<->gpu). My current impression is that
If my understanding is correct (please correct me if I misunderstood anything), I wonder in practice how much overhead we observed when running UCX vs low level APIs like NCCL or using RDMA verbs, on different hardwares? Thanks for all your help! Update: i'm also checking https://github.com/rapidsai/kvikio now; but this seems can be solved separately from Ray object transfer from first glance. |
|
Also as wondering if you are using Ray core (ray task/actor), or using Ray libraries like Train/Data? Knowing this might also influence where we implement them (in Ray core, or just in Ray libraries). |
|
@scv119 Thanks for your response. I have tested the performance of Ray's core (between CPUs) on Ethernet and InfiniBand. When I test on InfiniBand, I use IPoIB. The result shows the IPoIB doesn't make full use of the bandwidth. It is about only 20% of the total bandwidth. I test it on a cluster, and I want to make full use of the bandwidth. This is my start. Then I try to make gRPC support RDMA. But as you see below, it is not the right way. Based on my try, I prefer to use RDMA verbs to do this. Although the NCCL is a great library, it focuses on GPU and NVIDIA. The repository you mentioned I think it also focuses on GPUs. Besides, directly using RDMA verbs can greatly avoid modifying the ray's design. It only needs to add an RDMA communication lib under Ray's core. I try to implement the lib. In this way, It is easy to maintain the code. Last, I think Ray can support many kinds of work, not only deep learning. So I think starting from CPUs' communication is a good start. If the lib I mentioned is acceptable, I will give a preliminary example on GitHub ASAP. If there are some bugs, please help me. |
|
Apologies for the late reply here.
I don't think that impression is totally accurate. NCCL was initially created as a library to leverage collectives communication and make use of technologies such as NVLink, but later it had verbs (and you can even run verbs in NCCL with a UCX plugin and p2p communication introduced. On the other hand, UCX was formed as a consortium from various companies and Mellanox (which is today part of NVIDIA) has been involved since the beginning, bringing in verbs support from its early days. High performance is a core principle for both UCX and NCCL, like with everything there will be differences due to implementation details but I strongly believe they will be comparable overall, although I am not familiar with any benchmarks that compare various performance criteria between both. With the above said, NCCL's biggest advantage is that it's designed with collectives in mind, so if you want/can use collectives you can't go wrong there. On the other hand, UCX provides broader hardware support.
I think if you're going to write a library to add verbs support, you might as well just go instead with writing a wrapper to just plug to NCCL or UCX, they will both support verbs plus other hardware out-of-the-box (for example, NVLink) with a single API. There's nothing wrong with implementing verbs directly, but if you later decide to add support for NVLink, or shared memory transfers, or whatever other interconnect, then you will need to implement yet another library for that, eventually having to maintain multiple implementations for different interconnects, which is precisely the problem NCCL and UCX are trying to help users with. |
|
NCCL is designed for GPU-to-GPU communications within a single cluster and addresses endpoints by a contiguous range of integers that can change dynamically. I don't think that will work for many Ray use cases, and I also suspect it may be hard to fit into the current Ray networking stack One big application for RDMA is efficient data loading for deep learning. That requires CPU-to-GPU RDMA. UCX supports that, NCCL doesn't. UCX also uses standard addressing schemes instead of dynamic ranking. |
|
cc @xieus |
Can you explain this comment? I'm not sure I understand the definition of dynamic ranking in this case. From what I can tell, UCX would fit nicely into Ray and probably provide a better abstraction than directly using verbs. Besides RDMA reads/writes (gets/puts), you also get active messages and a variety of transports. Happy to help and explain more if this is of interest. |
|
I agree: UCX fits nicely into Ray. That was the point I was trying to make: it supports standard addressing and CPU-to-GPU RDMA. NCCL has different use cases than as a replacement for TCP/IP in Ray-style communications between Ray actors. NCCL is meant for "more structured" kinds of communication patterns between GPUs that occur in deep learning and scientific computing, and it is already easily used as such within Ray. |
|
any updates on this? |
|
So if I understand correctly, ray doesn't support RDMA yet? Any one can provide some guides about how to accelerate the data transmission between different nodes. |
|
Any updates on this? |
I have attempted to support RDMA technology in Ray. For simple Object transmission, it accelerated the data transfer. However, its impact was not significant in practical applications. Could you tell me what kind of applications I should build to verify its effectiveness? |
|
Related work: https://github.com/pwrliang/grpc-rdma by @pwrliang |
Thank you for your interest in RR-Compound, an RDMA-fused gRPC implementation. One of the advantages of using RR-Compound is its low development cost. By simply replacing the gRPC dependency with RR-Compound and recompiling Ray, you automatically benefit from RDMA. Please note that RR-Compound is based on an earlier version of gRPC (1.38.0), while Ray depends on version 1.57.1. Therefore, you may need to update the RR-Compound codebase accordingly. |
|
I've also drafted a streaming protocol for columnar data with off-loading via UCX or libfabric here: apache/arrow#43762 |
Description
I use Ray in an HPC cluster. The cluster has InfiniBand which has low latency and high bandwidth. Ray is based on gRPC and data transferring uses gRPC, too. I can use IPoIB(Internet Protocol over InfiniBand) in the cluster. In this way, I can not make full use of IB's bandwidth. It has the potential to get better performance.
Use case
I want to help ray to support RDMA for object transferring.
RDMA, which can reduce CPU interruptions for network processing and increase CPU utilization, is good at transferring memory data with a better performance. With the help of InfiniBand, I think ray's performance will be improved.
Tensorflow, which is also based on gRPC, has supported many ways for distributed environments such as grpc+verbs, and grpc+MPI, etc. The gRPC is used for controlling computing. The verbs and MPI are used for data transfer. As for Ray, I think they are familiar. I hope to separate the object store part and make it use RDMA as TensorFlow does.
I also do some tests on ray and MPI with different net environments. Ray and MPI used TCP over ethernet for data transfer as a baseline. MPI can speed up 16X with IPoIB and Ray can speed up about 10X. MPI can speed up 90X with RDMA and I think ray can get familiar improvement.
I have reviewed Ray’s code and it is a sophisticated project. I try to focus on the object store part in Ray’s withepaper. It help me but I still can find out where I can start with. I lost myself in the code ocean. And the whitepaper is different from the code. I cannot figure out how the data is transferred when the ray run. Are there any up-to-date documents I can refer to?
Where should I start if I want to contribute to the Ray project? Is any import class or file I should pay attention to?
The text was updated successfully, but these errors were encountered: