Split-Brain Autoencoders: Unsupervised Learning by Cross-Channel Prediction [Project Page]
Richard Zhang, Phillip Isola, Alexei A. Efros. In CVPR, 2017. (hosted on ArXiv)
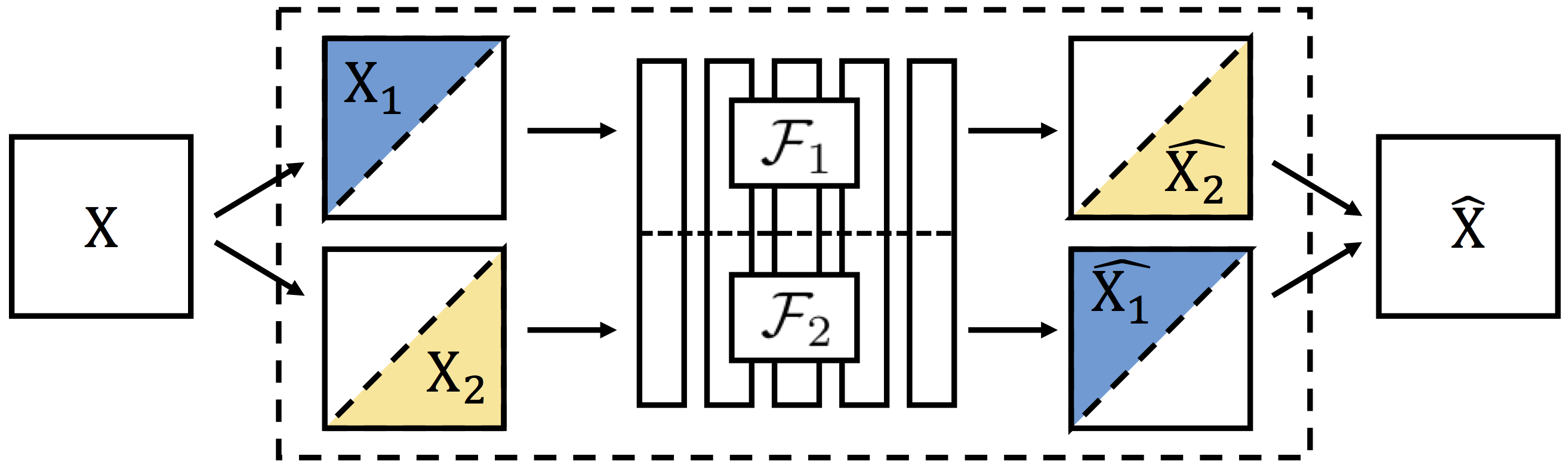
This repository contains a pre-trained Split-Brain Autoencoder network. The network achieves state-of-the-art results on several large-scale unsupervised representation learning benchmarks.
Clone the master branch of the respository using git clone -b master --single-branch https://github.com/richzhang/splitbrainauto.git
This code requires a working installation of Caffe. For guidelines and help with installation of Caffe, consult the installation guide and Caffe users group.
(1) Run ./resources/fetch_models.sh. This will load model model_splitbrainauto_clcl.caffemodel. It will also load model model_splitbrainauto_clcl_rs.caffemodel, which is the model with the rescaling method from Krähenbühl et al. ICLR 2016 applied. The rescaling method has been shown to improve fine-tuning performance in some models, and we use it for the PASCAL tests in Table 4 in the paper. Alternatively, download the models from here and put them in the models directory.
(2) To extract features, you can (a) use the main branch of Caffe and do color conversion outside of the network or (b) download and install a modified Caffe and not worry about color conversion.
(a) Color conversion outside of prototxt To extract features with the main branch of Caffe:
(i) Load the downloaded weights with model definition file deploy_lab.prototxt in the models directory. The input is blob data_lab, which is an image in Lab colorspace. You will have to do the Lab color conversion pre-processing outside of the network.
(b) Color conversion in prototxt You can also extract features with in-prototxt color version with a modified Caffe.
(i) Run ./resources/fetch_caffe.sh. This will load a modified Caffe into directory ./caffe-colorization.
(ii) Install the modified Caffe. For guidelines and help with installation of Caffe, consult the installation guide and Caffe users group.
(iii) Load the downloaded weights with model definition file deploy.prototxt in the models directory. The input is blob data, which is a non mean-centered BGR image.
If you find this model useful for your resesarch, please use this bibtex to cite.