访问:
安装记得点上注册到Path!!
Python 3.4+ 以上版本都自带 pip 工具
如果你没有Google Chrome那就装一个,装完后再下对应版本的Chrome Driver
将Chrome Driver.exe放在Python安装目录下

输入 pip install selenium 通过pip安装Selenium(抓阅读量用)
输入 pip install lxml (抓内容、转评赞用)
(如果还缺啥那就pip install 安装就完事儿了)
如果有啥bug我也不负责,反正就随便写的。 要说有什么可以Update的地方,那就是再把xpath学习一手让TestUnit.py直接抓取所有内容,输出到.xls中
在PowerShell或者其他Terminal中输入py 程序名儿.py 就可以运行程序了
- 用例weiboSpider.py(可扒取发布时间、机型、地点、博文、转评赞数量)
- 用例 TestUnit01.py 是我自己写来扒阅读量的,最后会生成一个.xls文件
想必看到这里你已经懂了,数据合并还是得手动。但是这已经减少80%的工作量了!知足了!有兴趣的话你再修改。欢迎pr!
这个用来抓阅读量。
运行之后,扫描二维码。然后全自动抓下来,生成Excel表格。
要抓哪一页就改pageIndex然后看到Terminal有个<<<<< done >>>> 就去文件夹下找到名为微博数据-2019xxxx的Excel文件。
如果不想要
阅读量三个字,请使用=RIGHT(A1,LEN(A1)-3)
注意:A1为A1单元格,3为你要删除前3个字符 s
具体参考:
这个用来抓大部分的内容,最后会生成一个csv,也可以用Excel打开,然后手动合并一下数据。
你需要修改weiboSpider.py中几项参数。
- cookie
- user_id
- filter
先登录https://passport.weibo.cn/signin/login,然后在地址栏输入https://weibo.cn。
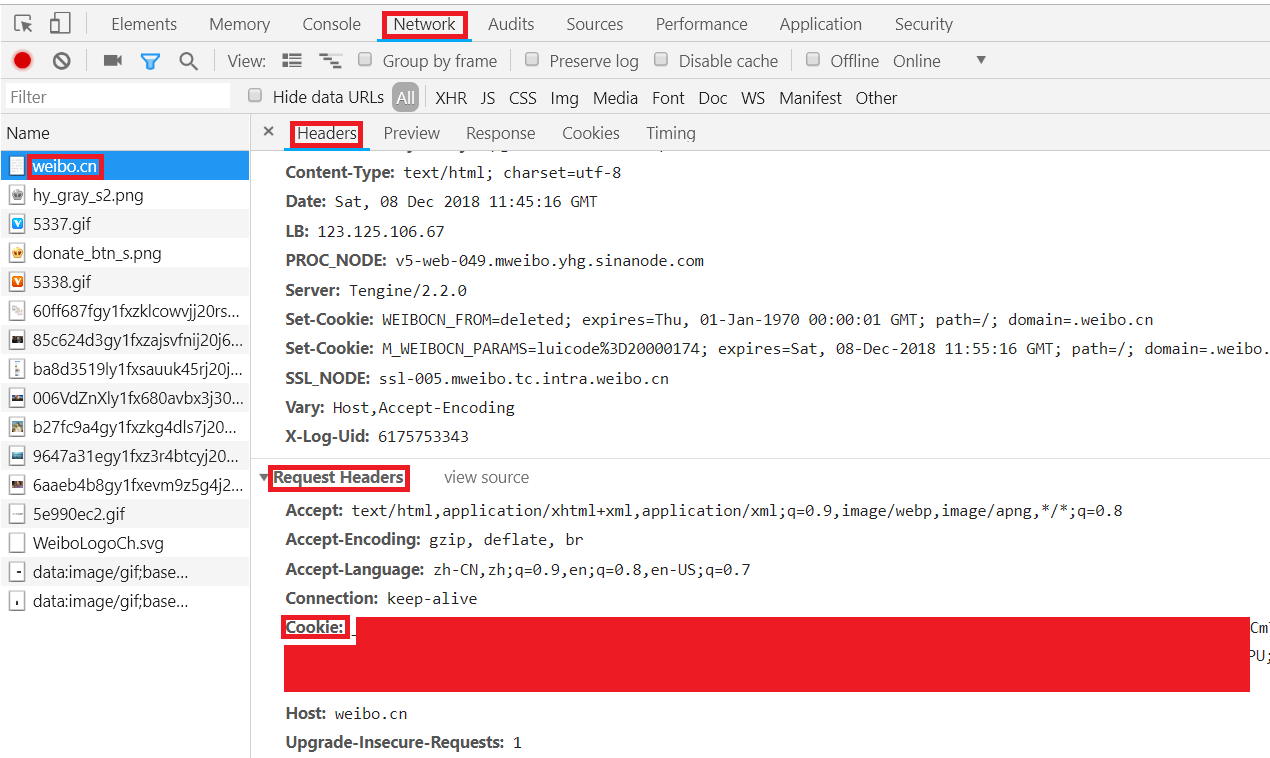
F12点击"Headers",其中"Request Headers"下,"Cookie"后的值即为我们要找的cookie值取出cookie。
具体操作见原作者GitHub
注意:每99条保存一次csv,如果不想爬了直接关闭终端
- 基础测试
- https://www.bilibili.com/video/av19057145/?p=13
- https://selenium-python-zh.readthedocs.io/en/latest/getting-started.html
- python爬虫从入门到放弃(八)之 Selenium库的使用
- 使用m.weibo.cn古老网页抓取教程weiboSpider.py
- xpath的使用
- 我的Chrome版本为74
- Chrome Driver忘记了.下载网址为http://chromedriver.storage.googleapis.com/index.html
- 除weiboSpider.py版权归原开发者所有,本Repo所有代码CC0,随意使用。(如果用的上的话,笑)