Predefined "blind" well data as measure of performance leads to over-fitting. #2
Comments
|
Thank you for raising this, Lukas. You mean because, even without using the well explicitly in the model, Any ideas for other measures, given that there are no more wells? Perhaps a I guess part of the problem is that any public measure could be trained On Tue, Oct 18, 2016, 18:21 Lukas Mosser [email protected] wrote:
|
|
One Idea could be to have a secret test well. Another could be to perform the prediction on all but one well, retaining the others E.g.: Final Score = Arithmetic Average of Score 1, Score 2, Score 3 I'm guessing, by no means an expert on this, but this would lead to a better estimate of an appropriate method rather than one set of parameters that are specifically designed to perform well on the proposed blind test well X. |
|
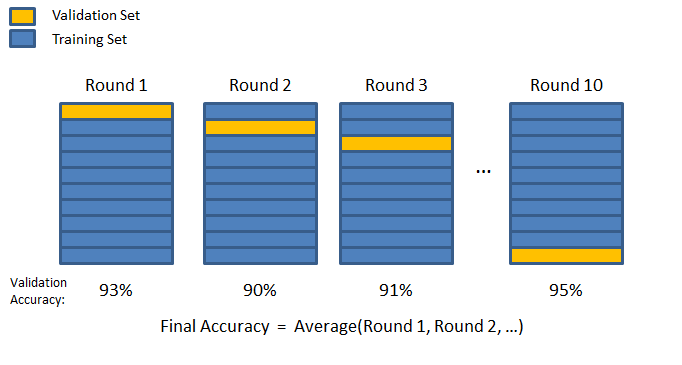
Actually I think Lukas is right. This is called k-fold cross-validation https://chrisjmccormick.files.wordpress.com/2013/07/10_fold_cv.png When compute the accuracy of the blind well alone, score variation is
Cordialement, Lorenzo Perozzi | PhD Geophysics linkedin https://www.linkedin.com/in/lperozzi github liamg logo http://www.liamg.ca |
{kind=link}
|
Excellent Visualization! I agree, I've seen even higher score variation it seems when running any of my code. |
|
Thank you again @LukasMosser for raising this issue of meta-overfitting, and @lperozzi for chiming in. We can (and expect to) learn as we go, so we'll look at k-fold CV as a score. That seems like a sensible approach. I have also got another plan — some fully blind data that we will not release. I'll post back to this issue if and when that's a reality. I guess all this is just something we have to live with in what is necessarily a limited universe of data. And I'm reading that it is (therefore) a common problem in machine learning contests. It makes me glad that there isn't $1 million at stake in this contest. Because we nearly went with that! (no, we didn't) |
|
@kwinkunks @lperozzi |
|
Hi everyone... A quick update on this issue of meta-overfitting. We have some labels for the STUART and CRAWFORD wells. These labels were not part of the data package, so they are truly blind. We will therefore be testing entries against them. We may also keep some type of k-fold CV in the mix. Brendon and I aim to propose a scoring strategy before next week. The goal is to be both analytically rigorous and fair to everyone. Either way, this means that all of the wells with labels in the data package can be used in training. |
|
Hi Matt, Brendon I am just starting today on the contest. I am trying to catch up on this issue, so to be sure I understand: we are to use all the wells for training, and in our submission we only include training (crossvalidated) scores? There's no validation on a blind well. I imagine entries can still include visual result (e.g. plot the predicted facies) on the STUART and CRAWFORD wells, but it is you and Brendon that will be doing the validation against STUART and CRAWFORD separately. Correct? |
|
Hey @mycarta ... Yes, use all the wells in training. And yes, we will validate against STUART and CRAWFORD, and it's that score that will count. I'm not sure yet if the k-fold CV score will count for anything, but I think it's probably the most useful thing to aim at. And yes, @CannedGeo should probably retrain his model, although I can do that too with his existing hyperparameters... it just might not be optimal. I suspect he's working on it in any case. |
|
@mycarta @kwinkunks If by retraining my model you mean banging head against wall, then yes, that is exactly what I've been doing!! This is maybe better presented in a separate question, but would it be totally against the rules to try and generate a PE for Alexander D and Kimzey A? I mean this is a machine learning exercise is it not?... And then include all wells in the model? |
|
@CannedGeo Yes, please do put that in an Issue of its own so other people will be more likely to see it. Short answer: you can do anything you like with the features, including generating new ones. Definitely. |
|
On the k-fold CV issue... I just made a small demo of stepwise dropout. Please have a look and see if you agree that it does what we've been talking about. cc @lperozzi @LukasMosser (I guess you will get notifications anyway, just making sure :) |
The contest outlines that the same well as in the publication will be used to judge the performance of the
proposed solutions. This can lead to overfitting by using the prediction capability for
the proposed well as a loss function.
Should another performance measure be used to compensate for overfitting?
The text was updated successfully, but these errors were encountered: