{kind=link}
{kind=link}
{kind=link}
Craw content from a website an all its subpages and store it in a database. Then use GPT create your own custom GPT and generate new content based on the crawled content.
screenshots:
https://chat.openai.com/g/g-RskOOlLFp-sumato-assistant
- Python 3.11
- Clone this repo
git clone https://github.com/sonpython/GPTSiteCrawler - craete a virtual environment:
python3 -m venv venv - activate the virtual environment:
source venv/bin/activate - Install dependencies:
pip install -r requirements.txt - Run the crawler:
python src/main.py https://example.com --selectors .main --annotate-size 2
> python src/main.py -h
usage: main.py [-h] [--output OUTPUT] [--stats STATS] [--selectors SELECTORS [SELECTORS ...]] [--max-links MAX_LINKS] [--annotate-size ANNOTATE_SIZE] url
Asynchronous web crawler
positional arguments:
url The starting URL for the crawl
options:
-h, --help show this help message and exit
--output OUTPUT Output file for crawled data
--stats STATS Output file for crawl statistics
--selectors SELECTORS [SELECTORS ...]
List of CSS selectors to extract text
--max-links MAX_LINKS
Maximum number of visited links to allow
--annotate-size ANNOTATE_SIZE
Chunk data.json to this file size in MB
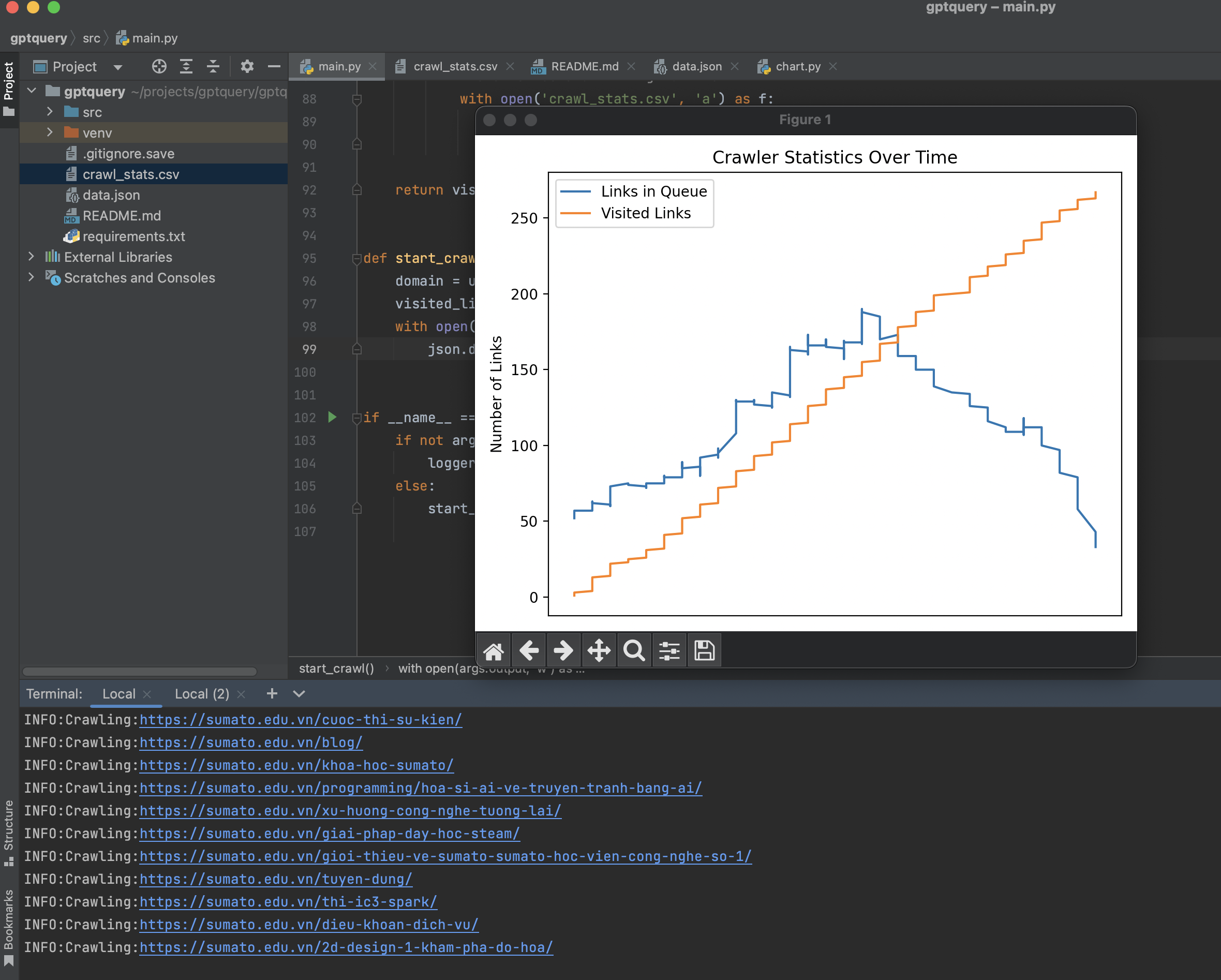
I've created a chart to help you understand how the crawler works. It's a bit of a simplification, but it should help you understand the basics.
You can run the chart with python src/chart.py in another terminal window to get the realtime chart updating the crawl progress.


env vars
CRAWLER_URL=https://example.com
CRAWLER_SELECTOR=.main
CRAWLER_CHUNK_SIZE=2 # in MBdocker build -t gpt-site-crawler .
docker run -it --rm gpt-site-crawler
(I borrow the bellows docs from @BuilderIO)
The crawl will generate a file called output.json at the root of this project. Upload that to OpenAI to create your custom assistant or custom GPT.
Use this option for UI access to your generated knowledge that you can easily share with others
Note: you may need a paid ChatGPT plan to create and use custom GPTs right now
- Go to https://chat.openai.com/
- Click your name in the bottom left corner
- Choose "My GPTs" in the menu
- Choose "Create a GPT"
- Choose "Configure"
- Under "Knowledge" choose "Upload a file" and upload the file you generated

Use this option for API access to your generated knowledge that you can integrate into your product.
- Go to https://platform.openai.com/assistants
- Click "+ Create"
- Choose "upload" and upload the file you generated
