基于pytorch的级联Bert用于中文命名实体识别。
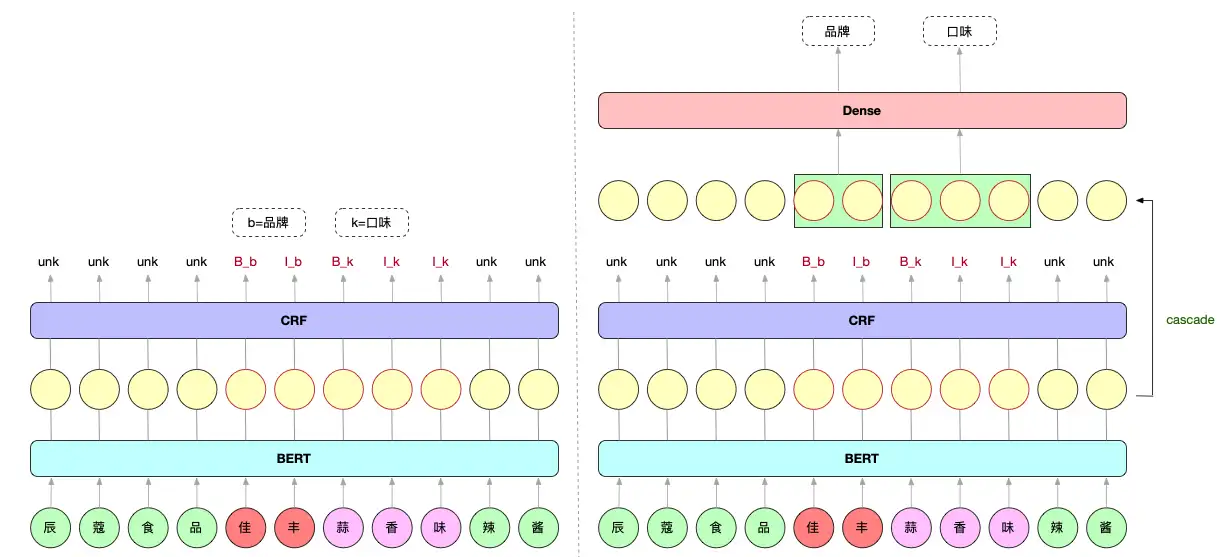
在进行序列标注的任务中,对于每一个类别都会分配一个BI标签。但是当类别数较多时,标签词表规模很大,相当于在每个字上都要做一次类别数巨多的分类任务,这种方式不太科学,也会影响效果【1】。从标签过多这个角度出发,卷友们提出把NER任务拆分成多任务学习,一个任务负责识别token是不是实体,另一个任务判断实体属于哪个类别。这样NER任务的lable 字典就只有"B"、"I"、"UNK"三个值了,速度嗖嗖的;而判断实体属于哪个类别用线性层就可,速度也很快,模型显存占用很少【2】。训练好的模型下载地址:链接:https://pan.baidu.com/s/17Sl6m2BbiU34P6VMYhDOTg?pwd=t5rp 提取码:t5rp
这里是以程序中的cner数据为例,其余两个数据集需要自己按照模板进行修改尝试,数据地址参考:基于pytorch的bert_bilstm_crf中文命名实体识别 (github.com)。如何修改:
- 1、在raw_data下是原始数据,新建一个process.py处理数据得到mid_data下的数据。
- 2、运行preprocess.cascade.py,得到final_data下的数据。具体相关的数据格式可以参考cner。
- 3、运行指令进行训练、验证和测试。
- 4、通过切换use_lstm和use_crf来确定是否使用bilstm或crf。
需要注意的是在数据处理的时候和训练的时候相关的参数要保持一致。模型结构【2】:
pytorch==1.6.0
tensorboasX
seqeval
pytorch-crf==0.7.2
transformers==4.4.0
python main.py \
--bert_dir="model_hub/chinese-bert-wwm-ext/" \
--data_dir="./data/cner/" \
--log_dir="./logs/" \
--output_dir="./checkpoints/" \
--bio_tags=3 \
--att_tags=9 \
--seed=123 \
--gpu_ids="0" \
--max_seq_len=150 \
--lr=3e-5 \
--crf_lr=3e-2 \
--other_lr=3e-4 \
--train_batch_size=32 \
--train_epochs=10 \
--eval_batch_size=32 \
--max_grad_norm=1 \
--warmup_proportion=0.1 \
--adam_epsilon=1e-8 \
--weight_decay=0.01 \
--lstm_hidden=128 \
--num_layers=1 \
--use_lstm='False' \
--use_crf='True' \
--dropout_prob=0.3 \
--dropout=0.3基于bert_crf的结果:
[eval] loss:24.5771 precision=0.9335 recall=0.9619 f1_score=0.9475
Saving model checkpoint to ./checkpoints/bert_crf
Load ckpt from ./checkpoints/bert_crf/model.pt
Use single gpu in: ['0']
_warn_prf(average, modifier, msg_start, len(result))
precision recall f1-score support
CONT 1.00 1.00 1.00 33
EDU 0.95 0.97 0.96 109
LOC 1.00 1.00 1.00 2
NAME 0.99 1.00 1.00 110
ORG 0.92 0.95 0.94 537
PRO 0.86 0.95 0.90 19
RACE 1.00 1.00 1.00 15
TITLE 0.93 0.96 0.95 750
UNK 0.00 0.00 0.00 0
micro avg 0.93 0.96 0.95 1575
macro avg 0.85 0.87 0.86 1575
weighted avg 0.93 0.96 0.95 1575
虞兔良先生:1963年12月出生,汉族,中国国籍,无境外永久居留权,浙江绍兴人,中共党员,MBA,经济师。
Load ckpt from ./checkpoints/bert_crf/model.pt
Use single gpu in: ['0']
{'NAME': [['虞兔良', 0]], 'RACE': [['汉族', 17]], 'CONT': [['中国国籍', 20]], 'LOC': [['浙江绍兴人', 34]], 'TITLE': [['中共党员', 40], ['经济师', 49]], 'EDU': [['MBA', 45]]}| models | loss | precision | recall | f1_score |
|---|---|---|---|---|
| bert | 3.9821 | 0.9192 | 0.9613 | 0.9398 |
| bert_bilstm | 3.5307 | 0.9333 | 0.9600 | 0.9465 |
| bert_crf | 24.5771 | 0.9335 | 0.9619 | 0.9475 |
| bert_bilstm_crf | 25.0705 | 0.9273 | 0.9549 | 0.9409 |
- 一种基于globalpointer的命名实体识别:https://github.com/taishan1994/pytorch_GlobalPointer_Ner
- 一种基于TPLinker_plus的命名实体识别:https://github.com/taishan1994/pytorch_TPLinker_Plus_Ner
- 一种基于bert_bilstm_crf的命名实体识别:https://github.com/taishan1994/pytorch_bert_bilstm_crf_ner
- 一种one vs rest方法进行命名实体识别:https://github.com/taishan1994/pytorch_OneVersusRest_Ner
- 一种级联Bert用于命名实体识别,解决标签过多问题:https://github.com/taishan1994/pytorch_Cascade_Bert_Ner
- 一种多头选择Bert用于命名实体识别:https://github.com/taishan1994/pytorch_Multi_Head_Selection_Ner
- 中文命名实体识别最新进展:https://github.com/taishan1994/awesome-chinese-ner
- 信息抽取三剑客:实体抽取、关系抽取、事件抽取:https://github.com/taishan1994/chinese_information_extraction
- 一种基于机器阅读理解的命名实体识别:https://github.com/taishan1994/BERT_MRC_NER_chinese
- W2NER:命名实体识别最新sota:https://github.com/taishan1994/W2NER_predict