Is there any way I can use yolov5 with opencv dnn #239
Comments
|
Yes @chaUAV it is possible, you need to export it using https://github.com/ultralytics/yolov5/blob/master/models/export.py, inside the file there is an usage example, then the model will be exported as an ONNX model and it can be imported in OpenCV using Or at least this is the supposed way, I found this issue doing that: #250 |
|
@chaUAV @edurenye I've added a pinned documentation issue now at the top of https://github.com/ultralytics/yolov5/issues for this, hopefully this will help everyone to understand the basic functionality. The INT64's remain one mystery among many in the export process though. |
|
Thanks @glenn-jocher I think it's the labels but I need to test, and I'm having some problems with Docker and me trying to update the nvidia drivers to 450, so it might take me a while. |
|
Thanks you guys, I had already export to onnx and use it with opencv but I got the same error as #250 is there anythings i could do to fix it? @glenn-jocher |
|
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions. |
|
This issue needs to be reopened @glenn-jocher |
|
@MohamedAliRashad sure. Are you trying to export an official YOLOv5 model for use with opencv? I can provide versions of these in ONNX format with outputs structured correctly, but they will lack NMS functionality. Is there a way to append an NMS module in ONNX? |
|
@glenn-jocher |
|
@MohamedAliRashad sorry I've just never used opencv dnn. Can you provide demo code for how this would work ideally? As I said I can provide fully functional exports in all supported formats for COCO and VOC trained YOLOv5 models. What format do you need it in exactly, and how is NMS handled? |
|
@glenn-jocher it's quite simple actually. then, we infer an input And finally we run thresholds for filtration with a code like this |
|
Has anyone done it properly? Using opencv-dnn to inference yolov5 models ... ? Is there any guide ? |
Hello? Can I take this onnx model and test it out? Thank you. |
Hello? The savings seem to have disappeared from the top over time. Could you tell me the url of the document? Thank you. |
|
@leeyunhome I've exported a YOLOv5s.onnx model at 640x640 here. It has two outputs, boxes (25200,4), and classes (25200,80).
|

Thank you for answer.
Thank you |
|
@leeyunhome this is an optimized ONNX model that we create using a private repo (ultralytics/yolov5-export). It's part of our paid product offerings. It works well for fixed output shapes, i.e. if you want an ONNX model to view 720p webcam streams. 25200 is the number of output points from a 640x640 image. You pass these through NMS to get your detections. |
|
Does anyone have a prepared notebook on yolov5 with OpenCV for live stream..? |
|
@vishal-nasre YOLOv5 runs inference out of the box on a variety of sources including remote streams (RTSP, HTTP etc.) and local webcams. See https://github.com/ultralytics/yolov5#quick-start-examples for details.
|

|
@edurenye @chaUAV @MohamedAliRashad @a954217436 @leeyunhome good news 😃! Your original issue may now be fixed ✅ in PR #4833 by @SamFC10. This PR implements architecture updates to allow for ONNX-exported YOLOv5 models to be used with OpenCV DNN. To receive this update:
Thank you for spotting this issue and informing us of the problem. Please let us know if this update resolves the issue for you, and feel free to inform us of any other issues you discover or feature requests that come to mind. Happy trainings with YOLOv5 🚀! |


|
Good to hear this update @glenn-jocher. |
|
@edurenye @chaUAV @MohamedAliRashad @a954217436 @leeyunhome steps for OpenCV DNN inference: # Export to ONNX
python export.py --weights yolov5s.pt --include onnx --simplify
# Inference
python detect.py --weights yolov5s.onnx # ONNX Runtime inference
# -- or --
python detect.py --weights yolov5s.onnx --dnn # OpenCV DNN inference |
|
Has anyone implemented inference through webcam & OpenCV using exported onnx model ?🤔 I knew |
|
@snehitvaddi read the README
|

@glenn-jocher @PauloMendes33 I use this code to run YOLO V5 with OpenCV DNN: import cv2
import time
import sys
import numpy as np
def build_model(is_cuda):
net = cv2.dnn.readNet("config_files/yolov5s.onnx")
if is_cuda:
print("Attempty to use CUDA")
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA_FP16)
else:
print("Running on CPU")
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU)
return net
INPUT_WIDTH = 640
INPUT_HEIGHT = 640
SCORE_THRESHOLD = 0.2
NMS_THRESHOLD = 0.4
CONFIDENCE_THRESHOLD = 0.4
def detect(image, net):
blob = cv2.dnn.blobFromImage(image, 1/255.0, (INPUT_WIDTH, INPUT_HEIGHT), swapRB=True, crop=False)
net.setInput(blob)
preds = net.forward()
return preds
def load_capture():
capture = cv2.VideoCapture("sample.mp4")
return capture
def load_classes():
class_list = []
with open("config_files/classes.txt", "r") as f:
class_list = [cname.strip() for cname in f.readlines()]
return class_list
class_list = load_classes()
def wrap_detection(input_image, output_data):
class_ids = []
confidences = []
boxes = []
rows = output_data.shape[0]
image_width, image_height, _ = input_image.shape
x_factor = image_width / INPUT_WIDTH
y_factor = image_height / INPUT_HEIGHT
for r in range(rows):
row = output_data[r]
confidence = row[4]
if confidence >= 0.4:
classes_scores = row[5:]
_, _, _, max_indx = cv2.minMaxLoc(classes_scores)
class_id = max_indx[1]
if (classes_scores[class_id] > .25):
confidences.append(confidence)
class_ids.append(class_id)
x, y, w, h = row[0].item(), row[1].item(), row[2].item(), row[3].item()
left = int((x - 0.5 * w) * x_factor)
top = int((y - 0.5 * h) * y_factor)
width = int(w * x_factor)
height = int(h * y_factor)
box = np.array([left, top, width, height])
boxes.append(box)
indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.25, 0.45)
result_class_ids = []
result_confidences = []
result_boxes = []
for i in indexes:
result_confidences.append(confidences[i])
result_class_ids.append(class_ids[i])
result_boxes.append(boxes[i])
return result_class_ids, result_confidences, result_boxes
def format_yolov5(frame):
row, col, _ = frame.shape
_max = max(col, row)
result = np.zeros((_max, _max, 3), np.uint8)
result[0:row, 0:col] = frame
return result
colors = [(255, 255, 0), (0, 255, 0), (0, 255, 255), (255, 0, 0)]
is_cuda = len(sys.argv) > 1 and sys.argv[1] == "cuda"
net = build_model(is_cuda)
capture = load_capture()
start = time.time_ns()
frame_count = 0
total_frames = 0
fps = -1
while True:
_, frame = capture.read()
if frame is None:
print("End of stream")
break
inputImage = format_yolov5(frame)
outs = detect(inputImage, net)
class_ids, confidences, boxes = wrap_detection(inputImage, outs[0])
frame_count += 1
total_frames += 1
for (classid, confidence, box) in zip(class_ids, confidences, boxes):
color = colors[int(classid) % len(colors)]
cv2.rectangle(frame, box, color, 2)
cv2.rectangle(frame, (box[0], box[1] - 20), (box[0] + box[2], box[1]), color, -1)
cv2.putText(frame, class_list[classid], (box[0], box[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, .5, (0,0,0))
if frame_count >= 30:
end = time.time_ns()
fps = 1000000000 * frame_count / (end - start)
frame_count = 0
start = time.time_ns()
if fps > 0:
fps_label = "FPS: %.2f" % fps
cv2.putText(frame, fps_label, (10, 25), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
cv2.imshow("output", frame)
if cv2.waitKey(1) > -1:
print("finished by user")
break
print("Total frames: " + str(total_frames))C++ version: #include <fstream>
#include <opencv2/opencv.hpp>
std::vector<std::string> load_class_list()
{
std::vector<std::string> class_list;
std::ifstream ifs("config_files/classes.txt");
std::string line;
while (getline(ifs, line))
{
class_list.push_back(line);
}
return class_list;
}
void load_net(cv::dnn::Net &net, bool is_cuda)
{
auto result = cv::dnn::readNet("config_files/yolov5s.onnx");
if (is_cuda)
{
std::cout << "Attempty to use CUDA\n";
result.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);
result.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA_FP16);
}
else
{
std::cout << "Running on CPU\n";
result.setPreferableBackend(cv::dnn::DNN_BACKEND_OPENCV);
result.setPreferableTarget(cv::dnn::DNN_TARGET_CPU);
}
net = result;
}
const std::vector<cv::Scalar> colors = {cv::Scalar(255, 255, 0), cv::Scalar(0, 255, 0), cv::Scalar(0, 255, 255), cv::Scalar(255, 0, 0)};
const float INPUT_WIDTH = 640.0;
const float INPUT_HEIGHT = 640.0;
const float SCORE_THRESHOLD = 0.2;
const float NMS_THRESHOLD = 0.4;
const float CONFIDENCE_THRESHOLD = 0.4;
struct Detection
{
int class_id;
float confidence;
cv::Rect box;
};
cv::Mat format_yolov5(const cv::Mat &source) {
int col = source.cols;
int row = source.rows;
int _max = MAX(col, row);
cv::Mat result = cv::Mat::zeros(_max, _max, CV_8UC3);
source.copyTo(result(cv::Rect(0, 0, col, row)));
return result;
}
void detect(cv::Mat &image, cv::dnn::Net &net, std::vector<Detection> &output, const std::vector<std::string> &className) {
cv::Mat blob;
auto input_image = format_yolov5(image);
cv::dnn::blobFromImage(input_image, blob, 1./255., cv::Size(INPUT_WIDTH, INPUT_HEIGHT), cv::Scalar(), true, false);
net.setInput(blob);
std::vector<cv::Mat> outputs;
net.forward(outputs, net.getUnconnectedOutLayersNames());
float x_factor = input_image.cols / INPUT_WIDTH;
float y_factor = input_image.rows / INPUT_HEIGHT;
float *data = (float *)outputs[0].data;
const int dimensions = 85;
const int rows = 25200;
std::vector<int> class_ids;
std::vector<float> confidences;
std::vector<cv::Rect> boxes;
for (int i = 0; i < rows; ++i) {
float confidence = data[4];
if (confidence >= CONFIDENCE_THRESHOLD) {
float * classes_scores = data + 5;
cv::Mat scores(1, className.size(), CV_32FC1, classes_scores);
cv::Point class_id;
double max_class_score;
minMaxLoc(scores, 0, &max_class_score, 0, &class_id);
if (max_class_score > SCORE_THRESHOLD) {
confidences.push_back(confidence);
class_ids.push_back(class_id.x);
float x = data[0];
float y = data[1];
float w = data[2];
float h = data[3];
int left = int((x - 0.5 * w) * x_factor);
int top = int((y - 0.5 * h) * y_factor);
int width = int(w * x_factor);
int height = int(h * y_factor);
boxes.push_back(cv::Rect(left, top, width, height));
}
}
data += 85;
}
std::vector<int> nms_result;
cv::dnn::NMSBoxes(boxes, confidences, SCORE_THRESHOLD, NMS_THRESHOLD, nms_result);
for (int i = 0; i < nms_result.size(); i++) {
int idx = nms_result[i];
Detection result;
result.class_id = class_ids[idx];
result.confidence = confidences[idx];
result.box = boxes[idx];
output.push_back(result);
}
}
int main(int argc, char **argv)
{
std::vector<std::string> class_list = load_class_list();
cv::Mat frame;
cv::VideoCapture capture("sample.mp4");
if (!capture.isOpened())
{
std::cerr << "Error opening video file\n";
return -1;
}
bool is_cuda = argc > 1 && strcmp(argv[1], "cuda") == 0;
cv::dnn::Net net;
load_net(net, is_cuda);
auto start = std::chrono::high_resolution_clock::now();
int frame_count = 0;
float fps = -1;
int total_frames = 0;
while (true)
{
capture.read(frame);
if (frame.empty())
{
std::cout << "End of stream\n";
break;
}
std::vector<Detection> output;
detect(frame, net, output, class_list);
frame_count++;
total_frames++;
int detections = output.size();
for (int i = 0; i < detections; ++i)
{
auto detection = output[i];
auto box = detection.box;
auto classId = detection.class_id;
const auto color = colors[classId % colors.size()];
cv::rectangle(frame, box, color, 3);
cv::rectangle(frame, cv::Point(box.x, box.y - 20), cv::Point(box.x + box.width, box.y), color, cv::FILLED);
cv::putText(frame, class_list[classId].c_str(), cv::Point(box.x, box.y - 5), cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 0, 0));
}
if (frame_count >= 30)
{
auto end = std::chrono::high_resolution_clock::now();
fps = frame_count * 1000.0 / std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
frame_count = 0;
start = std::chrono::high_resolution_clock::now();
}
if (fps > 0)
{
std::ostringstream fps_label;
fps_label << std::fixed << std::setprecision(2);
fps_label << "FPS: " << fps;
std::string fps_label_str = fps_label.str();
cv::putText(frame, fps_label_str.c_str(), cv::Point(10, 25), cv::FONT_HERSHEY_SIMPLEX, 1, cv::Scalar(0, 0, 255), 2);
}
cv::imshow("output", frame);
if (cv::waitKey(1) != -1)
{
capture.release();
std::cout << "finished by user\n";
break;
}
}
std::cout << "Total frames: " << total_frames << "\n";
return 0;
}More details can be find in this repository: https://github.com/doleron/yolov5-opencv-cpp-python |
|
@doleron thanks for the examples! I've added a link to your repo on the export tutorial in https://docs.ultralytics.com/yolov5/tutorials/model_export |
|
@doleron I think YOLOv5 expects inputs in [0, 1] without any mean subtraction, just dividing by 255 should be enough. blob = cv2.dnn.blobFromImage(image, 1/255.0, (INPUT_WIDTH, INPUT_HEIGHT), swapRB=True, crop=False) |
@SamFC10 You're right. I just edited the code. Thanks! |
|
I have to run yolov5 for my project but I don't know how to run it ?? previously we used opencv to load models , labels and weight |
@alimousavi1377 YOLOv5 does support this structure. Check #239 (comment) and #6309 (comment) for runnable examples of using YOLOv5 with built-in/custom models. In addition, if you really want to use OpenCV, check the C++/Python example few replies above to learn how to use .onnx files, OpenCV and YOLOv5. |
|
Thanks guys for this thread, helped me a lot. One question though: Any ideas how to use the YOLOv5 |
|
Hi @haimat ! As far I understand, talking about data augmentation only makes sense during the training time. Thus, once the model training is finished, the final model structure/topology does not reflect any of the augmentation hyperparametization set for the model training. The unique influence of augmentation is in the dataset preparation in order to achieve a better weight generalization power. |
|
@haimat Test Time Augmentation (TTA) flag Lines 395 to 400 in 1ff4370 @doleron see TTA tutorial for more info: YOLOv5 Tutorials
Good luck 🍀 and let us know if you have any other questions! |
|
@glenn-jocher Thanks for you reply, I was expecting something like that. So in other words, if I would like to use CV2+ONNX+TTA I would need to implement the TTA part in my own code, right? |
|
@haimat well that's an option. The TTA code can also be in the DetectMultiBackend() forward method. It just depends on what level the code is, right now it's at a low level inside the torch and torchvision models. |
|
Hi all, |
|
python detect.py --weights best.onnx --dnn --source 0 When I use the above command, it is working and detecting on my custom dataset well. The problem is it is showing the class label as a "person". But my custom dataset has only one class and it is labeled as a "ball". How to change it into ball.
|

|
@akbarali2019 for ONNX inference class names are handled automatically. For DNN inference you must pass your --data yaml to detect.py to retrieve class names: |
when I run this code in my own custom onnx file I'm getting this error: anybody help me to fix this? |
|
def wrap_detection(input_image, output_data): Return error
|
|
Just check the shape of the outs once. In my case, I had to format the code the following way. Checkout Source. |
|
dear Kukil thanks for your response |





|
dear Kukil thanks for your response |
|
Hi @alkhalisy, I checked it and yes I am able to reproduce the error. The yolov5s.onnx model is not the right one. Looks like something went wrong while converting to onnx. I found the other two models yolov5n.onnx and yolov5m.onnx working fine. while checking the shape of the Please try with the rest of the available models and verify. You can use the converter notebook to get the correct yolov5s.onnx model. Also, make sure to use torch==1.11 while doing so. I will be updating the code in sometime. |
|
Dear Kukil, thanks a lot for your help. you are right now it works with yolov5n.onnx waiting for your update on the code |
|
import cv2 Constants.INPUT_WIDTH = 640 Text parameters.FONT_FACE = cv2.FONT_HERSHEY_SIMPLEX ColorsBLACK = (0,0,0) Load class names.classesFile = "models/coco.names" Give the weight files to the model and load the network using them.modelWeights = "models/yolov5n.onnx" def image_show(frames): def video_capture(source): def draw_label(input_image, label, left, top): def pre_process(input_image, net): def post_process(input_image, outputs): def yolo5_detect(ca_images): if name == 'main':
Dear Kukil I try to capture from the webcam as in the above code the program worked with no error but slow is there any idea to solve this problem, especially since I need to use other models in the same program that gets the output image from one model and put it as input to other models, by this the execution will become very slow, but now I try just the Yolo model but is look slow |

The repo has been updated. |
|
cv2.error: OpenCV(4.6.0) D:\a\opencv-python\opencv-python\opencv\modules\dnn\src\onnx\onnx_importer.cpp:1040: error: (-2:Unspecified error) in function 'cv::dnn::dnn4_v20220524::ONNXImporter::handleNode'
how to fix this error |
|
Dear Kukil, thanks for the update, now it works with yolov5s but is still
very slow. is just 1 or 2 FPS may be hardware related? any suggestion?
-------------------------------------------------------------
Muhanad Abdul Elah Alkhalisy
*MSc Software **Engineering*
University of Information Technology and Communications
Mobile: +96407718662757
Email: ***@***.***
----------------------------------------------------------------
…On Mon, Jul 25, 2022 at 9:42 AM Kukil Kashyap Borgohain < ***@***.***> wrote:
Dear Kukil, thanks a lot for your help. you are right now it works with
yolov5n.onnx waiting for your update on the code
The repo has been updated.
—
Reply to this email directly, view it on GitHub
<#239 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/ALWYIEGPJNPRK3EZVIFKLCTVVYZNTANCNFSM4OL2CLYQ>
.
You are receiving this because you were mentioned.Message ID:
***@***.***>
|
the page is not found, is it expiredd? |
|
@Calviansyah 👋 Hello! Thanks for asking about Export Formats. YOLOv5 🚀 offers export to almost all of the common export formats. See our TFLite, ONNX, CoreML, TensorRT Export Tutorial for full details. FormatsYOLOv5 inference is officially supported in 11 formats: 💡 ProTip: Export to ONNX or OpenVINO for up to 3x CPU speedup. See CPU Benchmarks.
BenchmarksBenchmarks below run on a Colab Pro with the YOLOv5 tutorial notebook python benchmarks.py --weights yolov5s.pt --imgsz 640 --device 0Colab Pro V100 GPUColab Pro CPUExport a Trained YOLOv5 ModelThis command exports a pretrained YOLOv5s model to TorchScript and ONNX formats. python export.py --weights yolov5s.pt --include torchscript onnx💡 ProTip: Add Output: export: data=data/coco128.yaml, weights=['yolov5s.pt'], imgsz=[640, 640], batch_size=1, device=cpu, half=False, inplace=False, train=False, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=12, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['torchscript', 'onnx']
YOLOv5 🚀 v6.2-104-ge3e5122 Python-3.7.13 torch-1.12.1+cu113 CPU
Downloading https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5s.pt to yolov5s.pt...
100% 14.1M/14.1M [00:00<00:00, 274MB/s]
Fusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients
PyTorch: starting from yolov5s.pt with output shape (1, 25200, 85) (14.1 MB)
TorchScript: starting export with torch 1.12.1+cu113...
TorchScript: export success ✅ 1.7s, saved as yolov5s.torchscript (28.1 MB)
ONNX: starting export with onnx 1.12.0...
ONNX: export success ✅ 2.3s, saved as yolov5s.onnx (28.0 MB)
Export complete (5.5s)
Results saved to /content/yolov5
Detect: python detect.py --weights yolov5s.onnx
Validate: python val.py --weights yolov5s.onnx
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.onnx')
Visualize: https://netron.app/The 3 exported models will be saved alongside the original PyTorch model:
Netron Viewer is recommended for visualizing exported models:
Exported Model Usage Examples
python detect.py --weights yolov5s.pt # PyTorch
yolov5s.torchscript # TorchScript
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
yolov5s_openvino_model # OpenVINO
yolov5s.engine # TensorRT
yolov5s.mlmodel # CoreML (macOS only)
yolov5s_saved_model # TensorFlow SavedModel
yolov5s.pb # TensorFlow GraphDef
yolov5s.tflite # TensorFlow Lite
yolov5s_edgetpu.tflite # TensorFlow Edge TPU
yolov5s_paddle_model # PaddlePaddle
python val.py --weights yolov5s.pt # PyTorch
yolov5s.torchscript # TorchScript
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
yolov5s_openvino_model # OpenVINO
yolov5s.engine # TensorRT
yolov5s.mlmodel # CoreML (macOS Only)
yolov5s_saved_model # TensorFlow SavedModel
yolov5s.pb # TensorFlow GraphDef
yolov5s.tflite # TensorFlow Lite
yolov5s_edgetpu.tflite # TensorFlow Edge TPU
yolov5s_paddle_model # PaddlePaddleUse PyTorch Hub with exported YOLOv5 models: import torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.pt')
'yolov5s.torchscript ') # TorchScript
'yolov5s.onnx') # ONNX Runtime
'yolov5s_openvino_model') # OpenVINO
'yolov5s.engine') # TensorRT
'yolov5s.mlmodel') # CoreML (macOS Only)
'yolov5s_saved_model') # TensorFlow SavedModel
'yolov5s.pb') # TensorFlow GraphDef
'yolov5s.tflite') # TensorFlow Lite
'yolov5s_edgetpu.tflite') # TensorFlow Edge TPU
'yolov5s_paddle_model') # PaddlePaddle
# Images
img = 'https://ultralytics.com/images/zidane.jpg' # or file, Path, PIL, OpenCV, numpy, list
# Inference
results = model(img)
# Results
results.print() # or .show(), .save(), .crop(), .pandas(), etc.OpenCV DNN inferenceOpenCV inference with ONNX models: python export.py --weights yolov5s.pt --include onnx
python detect.py --weights yolov5s.onnx --dnn # detect
python val.py --weights yolov5s.onnx --dnn # validateC++ InferenceYOLOv5 OpenCV DNN C++ inference on exported ONNX model examples:
YOLOv5 OpenVINO C++ inference examples:
Good luck 🍀 and let us know if you have any other questions! |
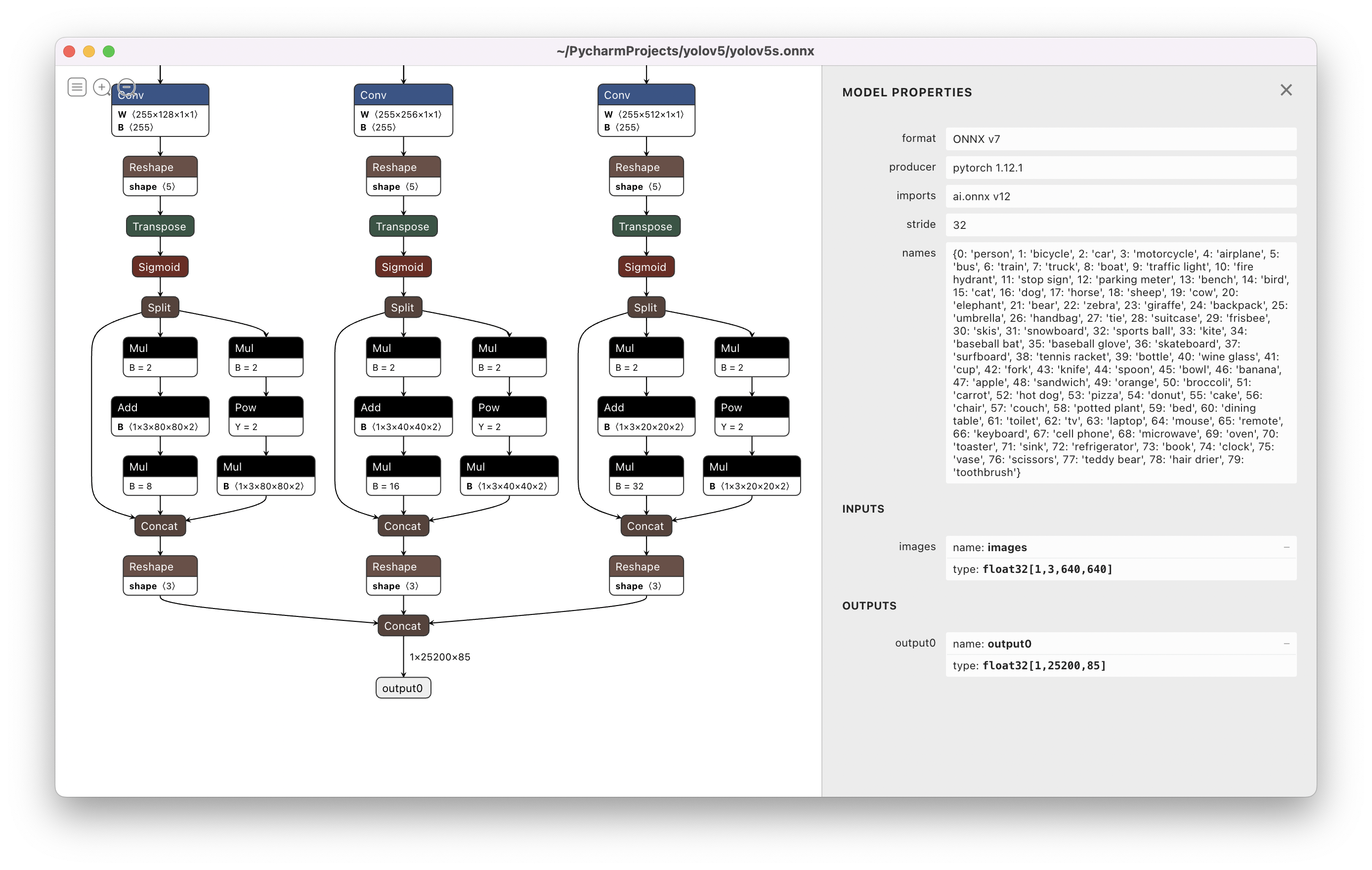
|
Dear, I try to remove P3 and P5 detection and still tp P4, and I do require a change in the Neck, and everything becomes well and works. When I try to delete C5 from the feature Extraction Backbone and do modifications in the neck, the error happened nc: 80 # number of classes [30,61, 62,45, 59,119] # P4/16 [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 head: [-1, 1, Conv, [256, 1, 1]], [-1, 1, Conv, [256, 3, 2]], [[20], 1, Detect, [nc, anchors]], # Detect( P4) |
|
@alkhalisy the issue you are encountering in modifying the backbone of the YOLOv5 model might be due to incorrect indexing or layer shapes. Since YOLOv5 expects a specific structure for its backbone and neck, modifying them without adjusting the subsequent layers, concatenations, or connections can lead to errors such as "IndexError: list index out of range". When modifying the YOLOv5 backbone and neck, ensure that the changes maintain the overall structure and input/output shapes required by the subsequent layers and the head. Additionally, verify that the connections between the backbone, neck, and head are updated accordingly. If you still encounter errors, you might consider sharing the complete modified configuration of the backbone, neck, and head, or provide more details about the specific changes you made. This will help in diagnosing the issue more effectively. |
🚀 Feature
Is there any way I can use yolov5 with opencv dnn
The text was updated successfully, but these errors were encountered: