Bark is supposed to be a small and easy-to-use library that uses PostgreSQL for collecting logs from multiple sources. It has a web server which can accept the logs using REST calls and for that reason we can run the server separately and can use client library (in progress) to send the logs to the server. But why are we writing yet another logger, aren't there many more already?

When we start off with smaller projects, logging is not an issue. You either do a fmt.Println or a log.Print and view and search for text in text files. However, as the app or the organisation grows in size and start creating multiple services and start logging more things, logging becomes more and more problematic. Filtering inside a log file becomes more difficult. Co-relating logs to form a single, isolated flow of events becomes a problem too. Sorting and searching that information across multiple large log files and keeping track of line numbers becomes confusing and debugging with the help of logs becomes a nightmare.
Now, there are pretty great projects, both open and proprietary out there that make log collection, search and analytics on terabyte scale possible. However, there are a few problems that we can observer:
- The more capable ones are either more costly, or more complex, or sometimes both.
- Setting up a dedicated logging solution is not always easy or possible given various constraints like time and manpower, testability, locality of data, cost, required expertise for the selected solution etc.)
- Then comes the learning curve of querying - different solutions have different query languages and varying nuances between them all.
So it takes time to install, configure and learn such solutions.
However, between the basic HTTP server and the enterprise scale, as we grow, we still need to be able to store, process, analyze and search through our logs.
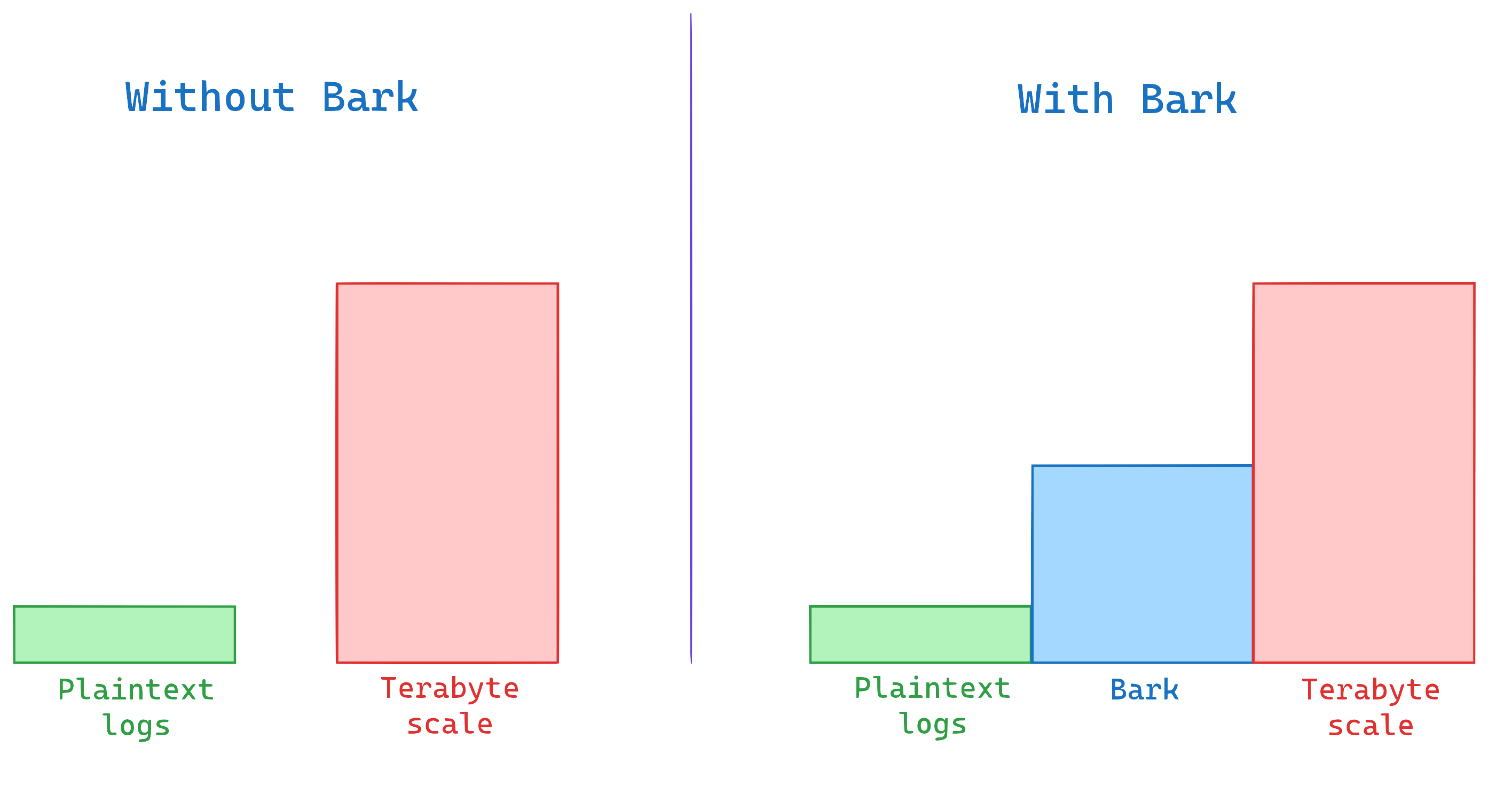
Bark aims to fill the gap that exists between simple file-based logging and a large log aggregation solution. Without Bark, a single developer or a small team working on a project would have to go through all the complex setup of an enterprise-level logging solution which they probably don't need or want at the outset.
Bark is:
- Easy to setup: We use PostgreSQL for storing logs. It is cross-platform and installing it is easy. You probably already have it installed for your other services anyway!
- Easy to configure: You just need to create a new database (or use an existing one), create a new table and start a server. That's it.
- Easy (or nothing) to learn: You probably already know SQL. You can use that knowledge to filter and analyze all your logs! There is nothing new to learn.
When the time comes, you can search through your logs as needed. You can dispose off anything that's unnecessary in one way or the other. For example, with Bark, you can easily do something like this :
- Delete logs that are more than 3 months old: Useful for saving storage
- Delete all logs that are of
INFOlevel: Useful when you want to delete all logs which do not represent any kind of failure or danger. - Delete all logs that are either
INFOorWARNINGlevel and were sent bypdf_printerservice between the dates:2023-06-03and2023-06-09: Useful when you know you had a problem that caused enormous amounts of logs to be emitted but the problem is solved now! - Delete everything older than a month except the ones with code
ABCDEF: Useful when you wanna clear off old logs but leave some for looking deeper into an old problem.
All of these are very easily doable using SQL!
We want this service to be available as a web service which can be called by other services to send in the log entries. Bark also aims to include a library which can be included in your golang project and be called from within the project using just a function.
Bark is supposed to scale alongside you till a point. Bark uses PostgreSQL for storing logs and is thus pretty performant.
However, it is worth noting that PostgreSQL is not designed to store enormous amounts of time-series data. But PostgreSQL is just good enough for mid-size installations (say about a dozen services) that has not gone global yet. So bark is not aimed at becoming the most powerful and flexible log aggregation service but useful enough for searching and filtering logs.
It has to be written in golang for the sake of being great at handling incoming traffic bursts, lining up the logs and sending them in a load-controlled manner to PostgreSQL (because PostgreSQL is not optimized for that kinda stuff).
- Go (Golang) version 1.21+ (if you want to compile the project)
- PostgreSQL database version 12+
If you have go version 1.21 or above installed, following are the steps to set up Bark on a machine after cloning the repository:
- Set the appropriate value for
BARK_DATABASE_URLenvironment variable. TheBARK_DATABASE_URLshould be of the formatpostgres://username:password@host:port/db?sslmode=disable. For example:export BARK_DATABASE_URL="postgres://vaibhav:[email protected]:5432/log_db?sslmode=disable" - Navigate to the directory containing the
go.modfile. - The dependencies are included in the
vendordirectory in the codebase, so you don't need to install them separately. - To create the required tables navigate to the
_nocode/db/migrationsfolder. Copy SQL commands from all the.up.sql, and run them in thepsqlterminal. Or you can use a migration tool like golang-migrate - Run the bark server using the command
go run main.go
To test if the library is up and running as expected, open a browser and navigate to the URL: localhost:8080/hello/vaibhav
You should see a text rendered on your browser saying Hello, vaibhav!
You can pull bark using docker as well:
docker pull techrail/bark:latest
Or you can directly run it using:
docker run techrail/bark:latest
Or you can use Docker Compose to run it. Once you have cloned the repository, you can cd to the project directory and run:
docker-compose up
And it should start running. You can then visit http://localhost:18080/hello/vaibhav and you should be greeted with the Hello, vaibhav! message!
NOTE: Please bear with us as we work fixing the docker versions.
Bark is a server. You can't use the server directly in any project. However, the project has a client which can be used. There is an example in the cmd/examples/client directory. So you can check that out.
When you are sending a log message to the server (via REST APIs), you must send either the Code (LMID) or the message. If you supply neither, the server will not save that entry to the database.
Also, you must send a valid JSON against the field moreData or else the call will fail.
It is more important to take care of these points when calling the endpoint for bulk insertions. When bulk insertions are required and you are calling the multiple insertion endpoint, even if one field in any of the elements being pushed has an invalid value, the entire batch of logs will be rejected (they will fail to get parsed).
- It is not a replacement for Plaintext logs - Bark should be able to write to a plaintext log file in parallel to throwing items into Postgres. In case Bark server cannot write to the database, it will emit your log messages on the server's STDOUT.
- It is not an APM - We don't want to throw in Application uptime or Performance Monitoring. Bark is not supposed to be a monitoring solution at all.
- It is not trying to replace any Terabyte-scale log aggregation service - e.g. ELK Stack, NewRelic, DataDog etc. are dedicated more towards enterprise requirements and have capability to handle terabytes of logs. Bark does not aim to act as a replacement of such services. It aims to be the stepping stone between plaintext and terabyte-scale, enterprise-ready solutions.
- It is not a CLI tool or a Web server at this point - Bark, at this time does not offer a Web Service or a CLI tool to view, filter or tail your logs. For that you would have to run a query against PostgreSQL directly using your terminal or GUI tool of your choice (tailing on logs might not be possible though).
Bark won't be here without the contributions we have gotten so far. Not would it be able to say beautifully that Logs are beautiful without the Social Media Preview and cover image Photo by Lora Ninova on Unsplash!