OH,又一个小说站点!是的,你说对了。
定义抓取网站的抓取规则,即可抓取信息,如起点图书列表规则如下:
rules = {
#书籍列表
book: {
list: {
url: 'http://all.qidian.com/book/bookstore.aspx?PageIndex=:page',
path: 'div.twoleft',
item: {
path: 'div.sw2,div.sw1',
segments: {
title: {
path: 'div.swb/span.swbt/a',
type: 'href'
},
last_chapter: {
path: 'div.swb/a.hui2',
type: 'href'
},
word_count: 'div.swc',
author: {
path: 'div.swd/a',
type: 'href',
save_url: false
},
last_updated_at: 'div.swe',
category_id: {
path: 'div.swa',
pattern: 'SubCategoryId=(\d+)',
category: 'regexp'
}
},
},
paging: {
path: 'div.storelistbottom',
current_page: 'a.f_s',
pages: 'a.f_a'
}
},
#书籍明细,如图片,公告,评论等
info: {
},
#书籍章节列表
chapter: {
},
#书籍正文信息
content: {
}
}
}
Source.create name: '起点中文网', code: 'qidian', url: 'http://qidian.com', rules: rules.to_yaml
目前才才是list节点
- 获取代码
git clone [email protected]:yuesmart/mori.git
- 更新数据库配置
cd mori
cp config/database.yml.local config/database.yml
vi config/database.yml
- 导入表结构
rake db:create
rake db:migrate
- 加载测试源
rake db:seed (加载测试源,如果需要)
- 小说信息
rake scraper:ranwen:book
- 小说章节信息
rake scraper:ranwen:chapter
- 消息章节正文
rake scraper:ranwen:content
- 解析章节之间关系
rake scraper:ranwen:associate
- 定期更新图书
rake scraper:ranwen:update
seeds.rb中已经内置了起点图书列表的规则,如果你已经执行过rake db:seed可以直接执行如下命令:
rake scraper:qidian:book
批量获取起点图书基本信息。
更多功能开发中,后期将以规则抓取为主,上面的燃文会被改写成规则抓取。
目前规则元数据格式不是最终确定的格式,因为才开始分析起点一个网站,也许后期会逐渐的完善、稳定下来
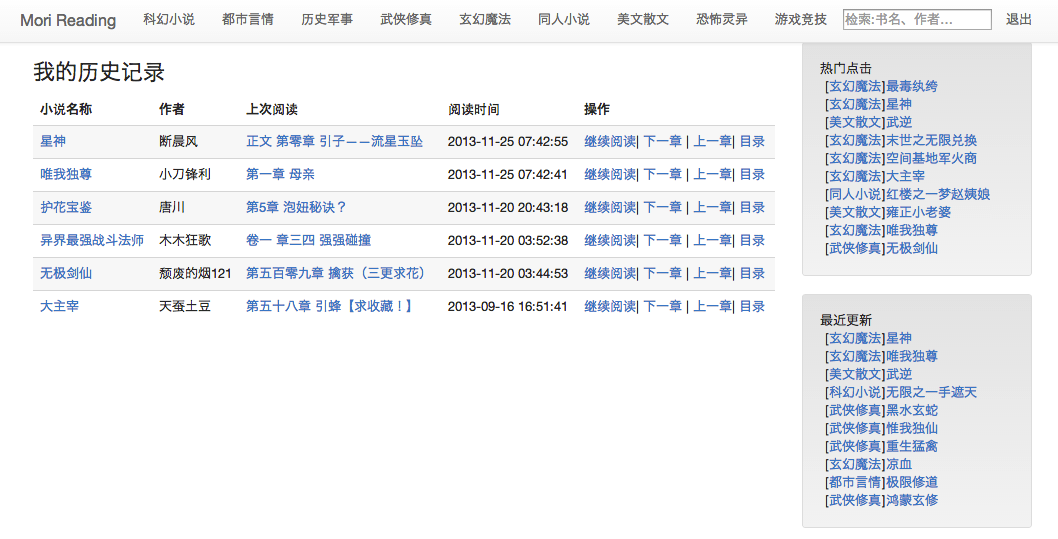
- 首页
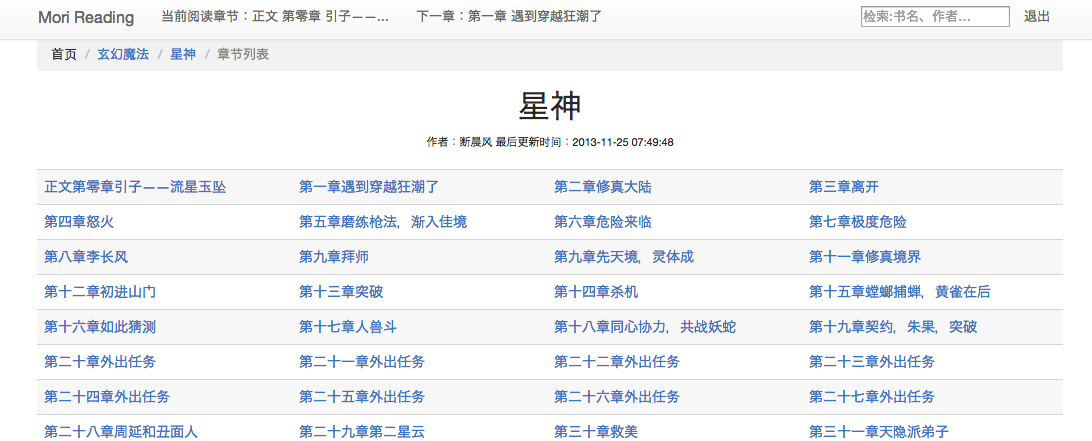
- 章节列表
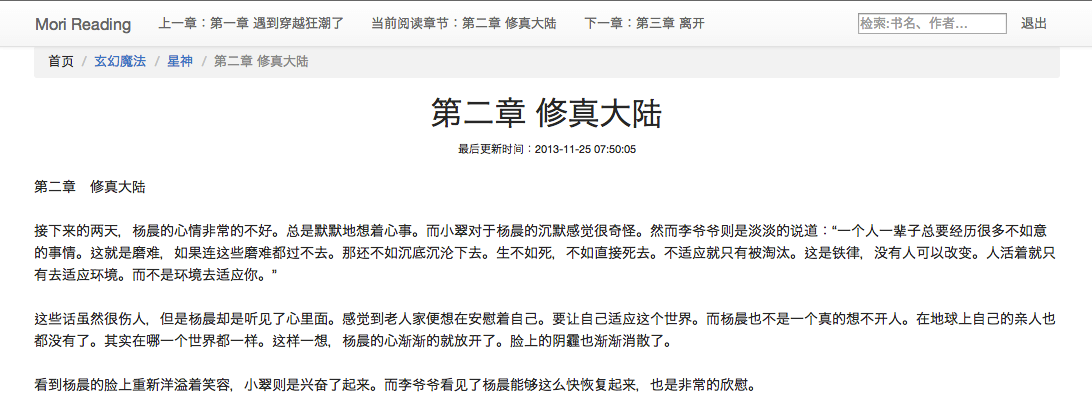
- 正文
Bug report or pull request are welcome.
- Fork it
- Create your feature branch (
git checkout -b my-new-feature) - Commit your changes (
git commit -am 'Add some feature') - Push to the branch (
git push origin my-new-feature) - Create new Pull Request
Please write unit test with your code if necessary.