buffer messages when websocket connection is interrupted #2871
Conversation
|
D'oh. Of course. This is per connection and this goes away when the connection is severed. |
|
I'm really unsure of how I could work around this to buffer messages to replay to clients when they reconnect. |
|
Yeah, it would need to go somewhere else. Right now, we create a zmq socket per websocket connection. That zmq socket is destroyed when the websocket connection is lost. What we would need to do is:
I think this is going to be tricky without moving the document state to the server, but may still be worth exploring. |
Yeah I still want that in the long term, it's hard to keep promising that in the short term though.
Yikes, alright. Do we just keep one extra zmq socket around then in that case. I see now how I was spinning some wheels hopelessly -- the zmq connection is created here when the websocket connection is created. |
For the lost connection case (not new tab, new browser, etc.), then replay should be fine, and all we need to track is the session_id, which is what identifies a browser session. This should work:
|
|
Saving the hairy cell:msg_id problem for another task makes sense to me. We can focus on the lost connection case, which will improve several real use cases. |
|
Based on conversations with Min, I'm going to take a new stab at this within the
|
|
|

9e4d902
to
569bb25
Compare
|
Just as you implements this particular mechanism, in case you want, you may also think of multi concurrent user notebooks in this form:
|
|
We're going to tackle multi user concurrent notebooks with a server side state of the notebook, which is not done today. This is only a band aid. Check out https://github.com/jupyterlab/jupyterlab-google-drive for the current alpha for realtime. |
|
I've pushed an implementation that works. It's still an unbounded list.
Things we could do:
|
- buffer is per-kernel - session_key is stored because only a single session can resume the buffer and we can't be sure - on any new connection to a kernel, buffer is flushed. If session_key matches, it is replayed. Otherwise, it is discarded. - buffer is an unbounded list for now
rather than establishing new connections fixes failure to resume shell channel
| def open(self, kernel_id): | ||
| super(ZMQChannelsHandler, self).open() | ||
| self.kernel_manager.notify_connect(kernel_id) | ||
|
|
||
| # on new connections, flush the message buffer | ||
| replay_buffer = self.kernel_manager.stop_buffering(kernel_id, self.session_key) |
There was a problem hiding this comment.
Ok cool you made the kernel manager dictate stopping the buffering
| self.log.info("Replaying %s buffered messages", len(replay_buffer)) | ||
| for channel, msg_list in replay_buffer: | ||
| stream = self.channels[channel] | ||
| self._on_zmq_reply(stream, msg_list) |
There was a problem hiding this comment.
What should we do if we fail during the replay?
Should we skip this test for now? |
No, I think it's a real bug. |
instead of in `create_stream`, which is not called on reconnect
- dismiss 'connection lost' dialog on reconnect - set busy status on reconnect (if not busy, idle will come soon after via kernel_ready)
|
Bug fixed. I also improved the dialog/status handling when connection is lost. |
|
Here's what it looks like now with a connection drop and reconnect in the middle of execution:
The dialog is dismissed automatically when the connection is restored. |
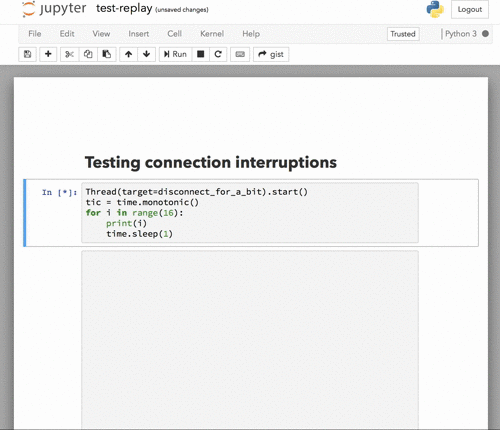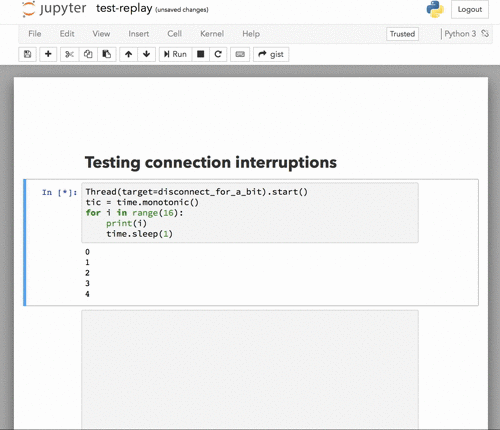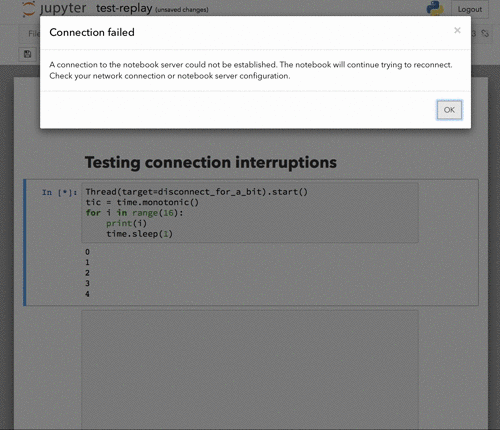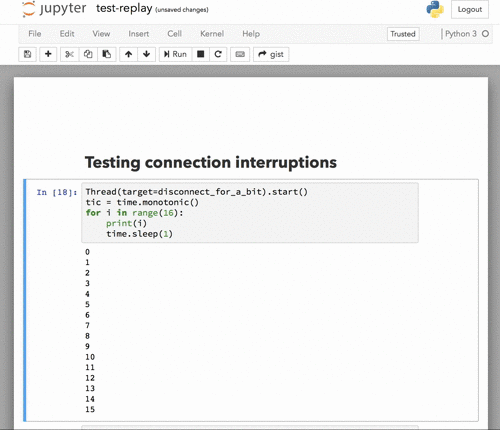
|
This is working pretty well. Even for a flaky VPN + wifi dropoff, I'm only losing one message within a one second gap. |
|
What if this were implemented as a response to a message from the frontend that said "hey, I was disconnected but I'm back, here's the last msg_id I got, please send the rest"? |
Oooooh, I like that. I mean, it will be a bit strange as we'll be putting a new API on top of the current API over the websockets though. |
|
@blink1073 that's definitely possible and would be more robust. To do that, we would need to maintain a cache of messages on all channels all the time, in case of dropped connections in the future, rather than only when connections are lost. Doing that points to a different mechanism, because it makes it inevitable that the cache gets huge, rather than possible. To do that, we need to spill to disk with an efficient culling mechanism. To me, that sounds like a job for sqlite. If I were doing that, I would make last_msg_id part of the websocket connect request to trigger the replay. |
|
If you use sqlite for messages, I would suggest default sqlite database should be in memory database. |
|
I think this is probably good to go ahead with for the time being as further enchancements are going to require a lot more coordination between the frontends and the server. |
|
@alexgarel I think it can't be in-memory by default because the main point of using sqlite would be to limit how much memory the message cache will take by spilling to disk. |
|
@rgbkrk & @minrk - First, sorry for posting this to a closed PR but it has all the necessary context. Second, I apologize for my long windedness. TL;DR: In looking at the buffering code, it seems like buffer replay never comes into play (at this time). I needed to look into buffering support relative to a recent NB2KG issue. Since NB2KG proxies the notebook's kernel management to a gateway server (Kernel Gateway or Enterprise Gateway), I was concerned that buffering replay wouldn't work. However, after looking into this more deeply, I find these behaviors between traditional notebook and nb2kg-enabled notebooks to be the same. I also find that when the network connection between the browser and notebook is dropped, the "replay" as indicated by the video above is not taking place from the buffering code, but, rather from ZMQ directly (at least that's my assumption). I say this because I don't see any debug entries about buffering messages and replaying or discarding them. Instead, those messages are produced only after one closes the notebook browser tab, then opens that same active notebook again (which Kyle mentions above as well in describing when the PR changes take place). As a result, I don't understand when the buffering replay will actually occur since it seems like re-opening an active notebook triggers the creation of a new session - which indirectly is part of the key (along with kernel_id) into the replayability of buffered messages. Do I have the correct understanding with respect to the state of buffering and its replay? If not, under what circumstances does the implemented buffering get replayed? Could you explain why session is part of the key for determining whether the buffered messages are to be replayed or not? I'm guessing it represents the "channel instances" since different connections of the same kernel instance will use different channels - is that right? If so, would it be possible to equate the channel "sets" from the previous (buffered) session to the new session and drop the use of session_key? Thank you for your time and increasing my understanding. |
|
They are attached to a session because otherwise the frontend has no way of associating output messages (by |
|
Thanks Kyle. So I think buffered message usage from NB2KG is doubly screwed (once replay is figured out) because the session_key generated in the Gateway server will be different than that generated in the (client) Notebook server where the messages are derived. Is this session key the same value as the session entry in each message (or can be derived from them)? If so, it would be nice if the message buffer initialized the session key in that manner. Any hints on how to trigger buffer replays (and not discards)? If not, I'll post in gitter. Thanks. |
|
I'm never in gitter, hopefully you'll find someone to help. I'd have to sit down again with the raw session messages to know for sure. Happy to meet about this at some point in the coming weeks (I'm out of town at the moment). |
Could it be associated with a notebook session id (instead of connection), that would be generated on client side (as a document DOM attribute), and that is given at websocket opening ? |
|
If the session id you're referring to is the one in the Seems like there needs to be some tolerance where the received messages can 'switch' to a different "channel set" in cases where the previous 'set' is no longer around. |
|
Does this sound related to jupyter/jupyter#83? |
Yes, I believe the issue you reference is the portion of this PR that is not addressed. That is, when a notebook is closed and re-opened, buffered messages received in the interim are discarded on the re-open due to it being a different WS connection. I took a run at this via #4105/#4110 but later learned the current implementation is working as designed. (I hadn't been able to get any messages to replay correctly, but Min's evidence on the corresponding PR showed its possible, so I dropped "my case".) |
|
The only way you can get messages to replay is if you lose connection, primarily on a remote server. |
|
If I put my laptop in hibernate with an open jupyterlab tab with a running notebook inside and then wake up the laptop again, no messages are replayed at all and it doesn't receive new messages either bewfore I actively tell it to run a new cell. In effect this means, that if I am e.g. running a cell that takes two days to complete, then I cannot see any results made after I put the computer in hibernate. So the only solution is to try and stay connected for as long as possible or the silly way: opening a remote desktop to the jupyter server, opening a browser on the remote and running the notebooks like that. Any solution expected soon? |
This adds an (unbounded) queue to the
ZMQChannelsHandlerto replay messages when a user reconnects.This assists those that lose a connection and keep their tab open. It does not help with the general problem of wanting a long running notebook to be saved in the background.