core: disable ptr::swap_nonoverlapping_one's block optimization on SPIR-V.
#83019
Conversation
I'm a bit surprised to see |
|
I’m not saying we shouldn’t change that, but one reason for |
Well you can, with There has to be unsafe code/some intrinsic at some point. Implementing the simpler operation (replace) with the much more complicated operation (swap) doesn't make a whole lot of sense. |
|
This complexity is not fundamental to Lines 260 to 274 in a59de37
|
|
A read+write mem::replace only calls copy_nonoverlapping twice, the basic swap implementation three times. The rest is moving an argument into a local variable, or moving a local variable into the return value, which happens in both cases. (And now with the optimized swap version, the difference is a whole lot more significant.) |
Correct, it's just that I'm not aware of I still stand by the 4 options in the PR description, but now MIR optimizations on |
Don't implement mem::replace with mem::swap. `swap` is a complicated operation, so this changes the implementation of `replace` to use `read` and `write` instead. See rust-lang#83019. I wrote there: > Implementing the simpler operation (replace) with the much more complicated operation (swap) doesn't make a whole lot of sense. `replace` is just read+write, and the primitive for moving out of a `&mut`. `swap` is for doing that to *two* `&mut` at the same time, which is both more niche and more complicated (as shown by `swap_nonoverlapping_bytes`). This could be especially interesting for `Option<VeryLargeStruct>::take()`, since swapping such a large structure with `swap_nonoverlapping_bytes` is going to be much less efficient than `ptr::write()`'ing a `None`. But also for small values where `swap` just reads/writes using temporary variable, this makes a `replace` or `take` operation simpler: 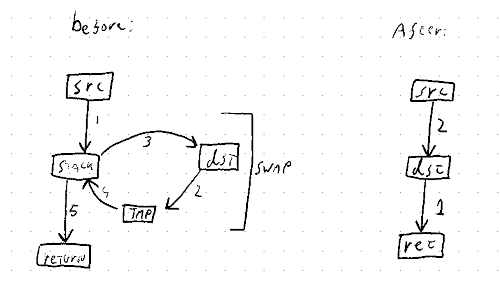
{kind=link}
|
☔ The latest upstream changes (presumably #83199) made this pull request unmergeable. Please resolve the merge conflicts. |
|
I'm comfortable with this landing, in that case. r=me after rebase. |
|
ping @eddyb ^ |
955761b
to
bc6af97
Compare
|
Oops, lost track of this (after it wasn't a priority anymore). @bors r=nagisa |
|
📌 Commit bc6af97 has been approved by |
core: disable `ptr::swap_nonoverlapping_one`'s block optimization on SPIR-V. SPIR-V primarily supports what it calls the "Logical addressing model" (and AFAIK for graphical shaders it's the only option), and what that implies is that there is no "memory" to uniformly address at some byte/word level, and that you can't really talk about values having a "raw representation" in terms of sequences of bytes. Therefore, the "block"-wise swapping optimization employed by `ptr::swap_nonoverlapping_one` (where a "block" is 32 bytes, currently), is fundamentally incompatible with SPIR-V "memory". As such, [Rust-GPU](https://github.com/EmbarkStudios/rust-gpu/)'s `rustc_codegen_spirv` backend cannot currently allow the use of `ptr::swap_nonoverlapping_one` - but that comes at a great price, since it's the building block of `mem::{swap,replace}`, and those in turn are used by e.g. `Option::take` and `Range`'s `Iterator` implementation (the latter blocking the use of `for i in 0..n` loops). There's 4 options I can see in terms of supporting `ptr::swap_nonoverlapping_one` in `rustc_codegen_spirv`: * legalize the block-wise swap loop back into swapping whole values, for SPIR-V * this is made borderline impossible by the fact that the size of the state "on the stack" is a block, and has to be expanded back to the appropriate size of the value being swapped, so in practice this would have to effectively pattern-match on the exact shape of the block-wise swapping algorithm, as a roundabout way of "patching `core::ptr` on the fly" * (**this PR**) disable the block-wise swap optimization altogether when `#[cfg(target_arch = "spirv")` * I've tested it and it does in fact allow compiling `for i in 0..n` loops, which was my primary motivation * main downside IMO is the fact that `core` now acknowledges an out-of-tree backend * as a counterpoint, any attempt to compile Rust to SPIR-V would run into this problem, one way or another * only enable the block-wise swap optimization on targets where it's been empirically proven to be an improvement * would avoid any surprises in terms of potentially-broken/inefficient codegen, in general * however, it may be universally applicable (thanks to caches), even if the optimal block size could differ * move low-level swapping into an intrinsic, where the backend can choose any optimization approach it wants * this also has an impact on MIR optimizations (cc `@rust-lang/wg-mir-opt)` - which currently cannot hope to make sense of e.g. `Option::take` despite it being effectively `_0 = *_1;` `*_1 = None;` `return;` * long-term this is my preferred approach, and I can start working on it if that's desired, but I wanted to confirm that this swapping optimization is the final blocker for [Rust-GPU](https://github.com/EmbarkStudios/rust-gpu/) supporting e.g. range `for` loops r? `@nagisa` cc `@rust-lang/libs`
Rollup of 7 pull requests Successful merges: - rust-lang#80525 (wasm64 support) - rust-lang#83019 (core: disable `ptr::swap_nonoverlapping_one`'s block optimization on SPIR-V.) - rust-lang#83717 (rustdoc: Separate filter-empty-string out into its own function) - rust-lang#83807 (Tests: Remove redundant `ignore-tidy-linelength` annotations) - rust-lang#83815 (ptr::addr_of documentation improvements) - rust-lang#83820 (Remove attribute `#[link_args]`) - rust-lang#83841 (Allow clobbering unsupported registers in asm!) Failed merges: r? `@ghost` `@rustbot` modify labels: rollup
SPIR-V primarily supports what it calls the "Logical addressing model" (and AFAIK for graphical shaders it's the only option), and what that implies is that there is no "memory" to uniformly address at some byte/word level, and that you can't really talk about values having a "raw representation" in terms of sequences of bytes. Therefore, the "block"-wise swapping optimization employed by
ptr::swap_nonoverlapping_one(where a "block" is 32 bytes, currently), is fundamentally incompatible with SPIR-V "memory".As such, Rust-GPU's
rustc_codegen_spirvbackend cannot currently allow the use ofptr::swap_nonoverlapping_one- but that comes at a great price, since it's the building block ofmem::{swap,replace}, and those in turn are used by e.g.Option::takeandRange'sIteratorimplementation (the latter blocking the use offor i in 0..nloops).There's 4 options I can see in terms of supporting
ptr::swap_nonoverlapping_oneinrustc_codegen_spirv:core::ptron the fly"#[cfg(target_arch = "spirv")for i in 0..nloops, which was my primary motivationcorenow acknowledges an out-of-tree backendOption::takedespite it being effectively_0 = *_1;*_1 = None;return;forloopsr? @nagisa cc @rust-lang/libs