Don't implement mem::replace with mem::swap. #83022
Conversation
|
r? @kennytm (rust-highfive has picked a reviewer for you, use r? to override) |
|
@bors try @rust-timer queue |
|
Awaiting bors try build completion. @rustbot label: +S-waiting-on-perf |
1 similar comment
This comment has been minimized.
This comment has been minimized.
|
⌛ Trying commit bf27819 with merge 9acd471bcf643c584381c0ff22e4d38a7617f313... |
This comment has been minimized.
This comment has been minimized.
|
FWIW I just tested this PR against Rust-GPU and it appears to handle the |
|
☀️ Try build successful - checks-actions |
|
Queued 9acd471bcf643c584381c0ff22e4d38a7617f313 with parent 5c6d3bf, future comparison URL. |
I don't believe that's true – assigning a |
|
@nagisa Nope, that just writes the tag of the Option, and nothing else. (Just like But looks like llvm is also smart enough to do that with the more compicated swap code: https://godbolt.org/z/TM1bcv |
Looking at the x86_64 assembly, changing it to be this shows off how the pub fn replace_large(dest: &mut Option<[u8; 127]>) -> Option<[u8; 127]> {
replace(dest, None)
}
Not smart enough in all cases, I guess? No idea how this case is different than yours, though. edit: discovered this weird thing, I mistakenly thought it was relevant but I missed something ugh. big shrug~ pub fn speedy_fast(x: &mut Option<[u64; 10]>) -> Option<[u64; 10]> {
std_replace(x, None)
}
// copied from std::mem::replace, just to be clear what's happening (same behavior with std::mem::replace)
fn std_replace(dest: &mut Option<[u64; 10]>, mut src: Option<[u64; 10]>) -> Option<[u64; 10]> {
std::mem::swap(dest, &mut src);
src
}
// manually inlined, should be the same? but isn't
pub fn big_slow_write(x: &mut Option<[u64; 10]>) -> Option<[u64; 10]> {
let mut blah = None;
std::mem::swap(x, &mut blah);
blah
} |
|
Finished benchmarking try commit (9acd471bcf643c584381c0ff22e4d38a7617f313): comparison url. Benchmarking this pull request likely means that it is perf-sensitive, so we're automatically marking it as not fit for rolling up. Please note that if the perf results are neutral, you should likely undo the rollup=never given below by specifying Importantly, though, if the results of this run are non-neutral do not roll this PR up -- it will mask other regressions or improvements in the roll up. @bors rollup=never |
🎉Quite a significant improvement! Everything is green, except for one +174% that pushed one average into the red. I suppose that's just a random outlier:
|

|
r? @eddyb |
|
Can it rerun perf without try? @rust-timer queue include=46449 |
|
Insufficient permissions to issue commands to rust-timer. |
|
@rust-timer queue include=46449 I sure have permissions, lets see what happens. EDIT: Looks like no, you can't rerun perf withouta another try build :( |
|
If nothing else, optimizing a simpler chunk of code is easier on the backend. While I sympathize with @SimonSapin's point about centralization of the unsafe code, I think The instruction count/walltime regression on the |
|
☀️ Try build successful - checks-actions |
|
Queued 6537b60dde68a3362e54e06e38e45445cd1e920d with parent 0cc64a3, future comparison URL. |
|
Finished benchmarking try commit (6537b60dde68a3362e54e06e38e45445cd1e920d): comparison url. Benchmarking this pull request likely means that it is perf-sensitive, so we're automatically marking it as not fit for rolling up. Please note that if the perf results are neutral, you should likely undo the rollup=never given below by specifying Importantly, though, if the results of this run are non-neutral do not roll this PR up -- it will mask other regressions or improvements in the roll up. @bors rollup=never |
|
Well, we're good to go, I guess! @bors r+ |
|
📌 Commit bf27819 has been approved by |
|
For what it’s worth I wasn’t saying in #83019 that we shouldn’t change anything, only that the current situation was not entirely accidental. These macro-level results look great. Since this effectively undoes #40454 for |
|
☀️ Test successful - checks-actions |
|
Thanks for this fix! Example where this (I think) was painful: taking and replacing packet size data in Options: |
Nice, that's a huge difference! Even with |
…iler-errors Use `load`+`store` instead of `memcpy` for small integer arrays I was inspired by rust-lang#98892 to see whether, rather than making `mem::swap` do something smart in the library, we could update MIR assignments like `*_1 = *_2` to do something smarter than `memcpy` for sufficiently-small types that doing it inline is going to be better than a `memcpy` call in assembly anyway. After all, special code may help `mem::swap`, but if the "obvious" MIR can just result in the correct thing that helps everything -- other code like `mem::replace`, people doing it manually, and just passing around by value in general -- as well as makes MIR inlining happier since it doesn't need to deal with all the complicated library code if it just sees a couple assignments. LLVM will turn the short, known-length `memcpy`s into direct instructions in the backend, but that's too late for it to be able to remove `alloca`s. In general, replacing `memcpy`s with typed instructions is hard in the middle-end -- even for `memcpy.inline` where it knows it won't be a function call -- is hard [due to poison propagation issues](https://rust-lang.zulipchat.com/#narrow/stream/187780-t-compiler.2Fwg-llvm/topic/memcpy.20vs.20load-store.20for.20MIR.20assignments/near/360376712). So because we know more about the type invariants -- these are typed copies -- rustc can emit something more specific, allowing LLVM to `mem2reg` away the `alloca`s in some situations. rust-lang#52051 previously did something like this in the library for `mem::swap`, but it ended up regressing during enabling mir inlining (rust-lang@cbbf06b), so this has been suboptimal on stable for ≈5 releases now. The code in this PR is narrowly targeted at just integer arrays in LLVM, but works via a new method on the [`LayoutTypeMethods`](https://doc.rust-lang.org/nightly/nightly-rustc/rustc_codegen_ssa/traits/trait.LayoutTypeMethods.html) trait, so specific backends based on cg_ssa can enable this for more situations over time, as we find them. I don't want to try to bite off too much in this PR, though. (Transparent newtypes and simple things like the 3×usize `String` would be obvious candidates for a follow-up.) Codegen demonstrations: <https://llvm.godbolt.org/z/fK8hT9aqv> Before: ```llvm define void `@swap_rgb48_old(ptr` noalias nocapture noundef align 2 dereferenceable(6) %x, ptr noalias nocapture noundef align 2 dereferenceable(6) %y) unnamed_addr #1 { %a.i = alloca [3 x i16], align 2 call void `@llvm.lifetime.start.p0(i64` 6, ptr nonnull %a.i) call void `@llvm.memcpy.p0.p0.i64(ptr` noundef nonnull align 2 dereferenceable(6) %a.i, ptr noundef nonnull align 2 dereferenceable(6) %x, i64 6, i1 false) tail call void `@llvm.memcpy.p0.p0.i64(ptr` noundef nonnull align 2 dereferenceable(6) %x, ptr noundef nonnull align 2 dereferenceable(6) %y, i64 6, i1 false) call void `@llvm.memcpy.p0.p0.i64(ptr` noundef nonnull align 2 dereferenceable(6) %y, ptr noundef nonnull align 2 dereferenceable(6) %a.i, i64 6, i1 false) call void `@llvm.lifetime.end.p0(i64` 6, ptr nonnull %a.i) ret void } ``` Note it going to stack: ```nasm swap_rgb48_old: # `@swap_rgb48_old` movzx eax, word ptr [rdi + 4] mov word ptr [rsp - 4], ax mov eax, dword ptr [rdi] mov dword ptr [rsp - 8], eax movzx eax, word ptr [rsi + 4] mov word ptr [rdi + 4], ax mov eax, dword ptr [rsi] mov dword ptr [rdi], eax movzx eax, word ptr [rsp - 4] mov word ptr [rsi + 4], ax mov eax, dword ptr [rsp - 8] mov dword ptr [rsi], eax ret ``` Now: ```llvm define void `@swap_rgb48(ptr` noalias nocapture noundef align 2 dereferenceable(6) %x, ptr noalias nocapture noundef align 2 dereferenceable(6) %y) unnamed_addr #0 { start: %0 = load <3 x i16>, ptr %x, align 2 %1 = load <3 x i16>, ptr %y, align 2 store <3 x i16> %1, ptr %x, align 2 store <3 x i16> %0, ptr %y, align 2 ret void } ``` still lowers to `dword`+`word` operations, but has no stack traffic: ```nasm swap_rgb48: # `@swap_rgb48` mov eax, dword ptr [rdi] movzx ecx, word ptr [rdi + 4] movzx edx, word ptr [rsi + 4] mov r8d, dword ptr [rsi] mov dword ptr [rdi], r8d mov word ptr [rdi + 4], dx mov word ptr [rsi + 4], cx mov dword ptr [rsi], eax ret ``` And as a demonstration that this isn't just `mem::swap`, a `mem::replace` on a small array (since replace doesn't use swap since rust-lang#83022), which used to be `memcpy`s in LLVM changes in IR ```llvm define void `@replace_short_array(ptr` noalias nocapture noundef sret([3 x i32]) dereferenceable(12) %0, ptr noalias noundef align 4 dereferenceable(12) %r, ptr noalias nocapture noundef readonly dereferenceable(12) %v) unnamed_addr #0 { start: %1 = load <3 x i32>, ptr %r, align 4 store <3 x i32> %1, ptr %0, align 4 %2 = load <3 x i32>, ptr %v, align 4 store <3 x i32> %2, ptr %r, align 4 ret void } ``` but that lowers to reasonable `dword`+`qword` instructions still ```nasm replace_short_array: # `@replace_short_array` mov rax, rdi mov rcx, qword ptr [rsi] mov edi, dword ptr [rsi + 8] mov dword ptr [rax + 8], edi mov qword ptr [rax], rcx mov rcx, qword ptr [rdx] mov edx, dword ptr [rdx + 8] mov dword ptr [rsi + 8], edx mov qword ptr [rsi], rcx ret ```
Optimize `ptr::replace` rust-lang#83022 optimized `mem::replace` to reduce the number of `memcpy`s. `ptr::replace`, which is [documented to behave just like `mem::replace`](https://doc.rust-lang.org/nightly/std/ptr/fn.replace.html), was not optimized however, leading to [worse code](https://godbolt.org/z/T3hdEEdfe) and missed optimizations. This PR simply forwards `ptr::replace` to `mem::replace` to take advantage of the better implementation.
Rollup merge of rust-lang#122601 - joboet:ptr_replace, r=workingjubilee Optimize `ptr::replace` rust-lang#83022 optimized `mem::replace` to reduce the number of `memcpy`s. `ptr::replace`, which is [documented to behave just like `mem::replace`](https://doc.rust-lang.org/nightly/std/ptr/fn.replace.html), was not optimized however, leading to [worse code](https://godbolt.org/z/T3hdEEdfe) and missed optimizations. This PR simply forwards `ptr::replace` to `mem::replace` to take advantage of the better implementation.
swapis a complicated operation, so this changes the implementation ofreplaceto usereadandwriteinstead.See #83019.
I wrote there:
This could be especially interesting for
Option<VeryLargeStruct>::take(), since swapping such a large structure withswap_nonoverlapping_bytesis going to be much less efficient thanptr::write()'ing aNone.But also for small values where
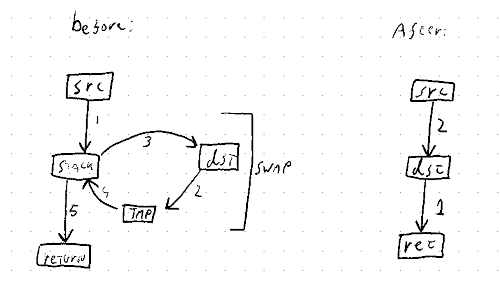
swapjust reads/writes using temporary variable, this makes areplaceortakeoperation simpler: