Releases: databricks/koalas
Version 1.8.2
Koalas 1.8.2 is a maintenance release.
Koalas is officially included in PySpark as pandas API on Spark in Apache Spark 3.2. In Apache Spark 3.2+, please use Apache Spark directly.
Although moving to pandas API on Spark is recommended, Koalas 1.8.2 still works with Spark 3.2 (#2203).
Improvements and bug fixes
- _builtin_table import in groupby apply (changed in pandas>=1.3.0). (#2184)
Version 1.8.1
Koalas 1.8.1 is a maintenance release. Koalas will be officially included in PySpark in the upcoming Apache Spark 3.2. In Apache Spark 3.2+, please use Apache Spark directly.
Improvements and bug fixes
- Remove the upperbound for numpy. (#2166)
- Allow Python 3.9 when the underlying PySpark is 3.1 and above. (#2167)
Along with the following fixes:
Version 1.8.0
Koalas 1.8.0 is the last minor release because Koalas will be officially included in PySpark in the upcoming Apache Spark 3.2. In Apache Spark 3.2+, please use Apache Spark directly.
Categorical type and ExtensionDtype
We added the support of pandas' categorical type (#2064, #2106).
>>> s = ks.Series(list("abbccc"), dtype="category")
>>> s
0 a
1 b
2 b
3 c
4 c
5 c
dtype: category
Categories (3, object): ['a', 'b', 'c']
>>> s.cat.categories
Index(['a', 'b', 'c'], dtype='object')
>>> s.cat.codes
0 0
1 1
2 1
3 2
4 2
5 2
dtype: int8
>>> idx = ks.CategoricalIndex(list("abbccc"))
>>> idx
CategoricalIndex(['a', 'b', 'b', 'c', 'c', 'c'],
categories=['a', 'b', 'c'], ordered=False, dtype='category')
>>> idx.codes
Int64Index([0, 1, 1, 2, 2, 2], dtype='int64')
>>> idx.categories
Index(['a', 'b', 'c'], dtype='object')and ExtensionDtype as type arguments to annotate return types (#2120, #2123, #2132, #2127, #2126, #2125, #2124):
def func() -> ks.Series[pd.Int32Dtype()]:
...Other new features, improvements and bug fixes
We added the following new features:
DataFrame:
Series:
DatetimeIndex:
Along with the following fixes:
- Support tuple to (DataFrame|Series).replace() (#2095)
- Check index_dtype and data_dtypes more strictly. (#2100)
- Return actual values via toPandas. (#2077)
- Add lines and orient to read_json and to_json to improve error message (#2110)
- Fix isin to accept numpy array (#2103)
- Allow multi-index column names for inferring return type schema with names. (#2117)
- Add a short JDBC user guide (#2148)
- Remove upper bound pandas 1.2 (#2141)
- Standardize exceptions of arithmetic operations on Datetime-like data (#2101)
Version 1.7.0
Switch the default plotting backend to Plotly
We switched the default plotting backend from Matplotlib to Plotly (#2029, #2033). In addition, we added more Plotly methods such as DataFrame.plot.kde and Series.plot.kde (#2028).
import databricks.koalas as ks
kdf = ks.DataFrame({
'a': [1, 2, 2.5, 3, 3.5, 4, 5],
'b': [1, 2, 3, 4, 5, 6, 7],
'c': [0.5, 1, 1.5, 2, 2.5, 3, 3.5]})
kdf.plot.hist()
Plotting backend can be switched to matplotlib by setting ks.options.plotting.backend to matplotlib.
ks.options.plotting.backend = "matplotlib"Add Int64Index, Float64Index, DatatimeIndex
We added more types of Index such as Index64Index, Float64Index and DatetimeIndex (#2025, #2066).
When creating an index, Index instance is always returned regardless of the data type.
But now Int64Index, Float64Index or DatetimeIndex is returned depending on the data type of the index.
>>> type(ks.Index([1, 2, 3]))
<class 'databricks.koalas.indexes.numeric.Int64Index'>
>>> type(ks.Index([1.1, 2.5, 3.0]))
<class 'databricks.koalas.indexes.numeric.Float64Index'>
>>> type(ks.Index([datetime.datetime(2021, 3, 9)]))
<class 'databricks.koalas.indexes.datetimes.DatetimeIndex'>In addition, we added many properties for DatetimeIndex such as year, month, day, hour, minute, second, etc. (#2074) and added APIs for DatetimeIndex such as round(), floor(), ceil(), normalize(), strftime(), month_name() and day_name() (#2082, #2086, #2089).
Create Index from Series or Index objects
Index can be created by taking Series or Index objects (#2071).
>>> kser = ks.Series([1, 2, 3], name="a", index=[10, 20, 30])
>>> ks.Index(kser)
Int64Index([1, 2, 3], dtype='int64', name='a')
>>> ks.Int64Index(kser)
Int64Index([1, 2, 3], dtype='int64', name='a')
>>> ks.Float64Index(kser)
Float64Index([1.0, 2.0, 3.0], dtype='float64', name='a')>>> kser = ks.Series([datetime(2021, 3, 1), datetime(2021, 3, 2)], index=[10, 20])
>>> ks.Index(kser)
DatetimeIndex(['2021-03-01', '2021-03-02'], dtype='datetime64[ns]', freq=None)
>>> ks.DatetimeIndex(kser)
DatetimeIndex(['2021-03-01', '2021-03-02'], dtype='datetime64[ns]', freq=None)Extension dtypes support
We added basic extension dtypes support (#2039).
>>> kdf = ks.DataFrame(
... {
... "a": [1, 2, None, 3],
... "b": [4.5, 5.2, 6.1, None],
... "c": ["A", "B", "C", None],
... "d": [False, None, True, False],
... }
... ).astype({"a": "Int32", "b": "Float64", "c": "string", "d": "boolean"})
>>> kdf
a b c d
0 1 4.5 A False
1 2 5.2 B <NA>
2 <NA> 6.1 C True
3 3 NaN <NA> False
>>> kdf.dtypes
a Int32
b float64
c string
d boolean
dtype: objectThe following types are supported per the installed pandas:
- pandas >= 0.24
Int8DtypeInt16DtypeInt32DtypeInt64Dtype
- pandas >= 1.0
BooleanDtypeStringDtype
- pandas >= 1.2
Float32DtypeFloat64Dtype
Binary operations and type casting are supported:
>>> kdf.a + kdf.b
0 5
1 7
2 <NA>
3 <NA>
dtype: Int64
>>> kdf + kdf
a b
0 2 8
1 4 10
2 <NA> 12
3 6 <NA>
>>> kdf.a.astype('Float64')
0 1.0
1 2.0
2 <NA>
3 3.0
Name: a, dtype: Float64Other new features, improvements and bug fixes
We added the following new features:
koalas:
Series:
align(#2019)
DataFrame:
Along with the following fixes:
- PySpark 3.1.1 Support
- Preserve index for statistical functions with axis==1 (#2036)
- Use iloc to make sure it retrieves the first element (#2037)
- Fix numeric_only to follow pandas (#2035)
- Fix DataFrame.merge to work properly (#2060)
- Fix astype(str) for some data types (#2040)
- Fix binary operations Index by Series (#2046)
- Fix bug on pow and rpow (#2047)
- Support bool list-like column selection for loc indexer (#2057)
- Fix window functions to resolve (#2090)
- Refresh GitHub workflow matrix (#2083)
- Restructure the hierarchy of Index unit tests (#2080)
- Fix to delegate dtypes (#2061)
Version 1.6.0
Improved Plotly backend support
We improved plotting support by implementing pie, histogram and box plots with Plotly plot backend. Koalas now can plot data with Plotly via:
-
DataFrame.plot.pieandSeries.plot.pie(#1971)

-
DataFrame.plot.histandSeries.plot.hist(#1999)

-
Series.plot.box(#2007)

In addition, we optimized histogram calculation as a single pass in DataFrame (#1997) instead of launching each job to calculate each Series in DataFrame.
Operations between Series and Index
The operations between Series and Index are now supported as below (#1996):
>>> kser = ks.Series([1, 2, 3, 4, 5, 6, 7])
>>> kidx = ks.Index([0, 1, 2, 3, 4, 5, 6])
>>> (kser + 1 + 10 * kidx).sort_index()
0 2
1 13
2 24
3 35
4 46
5 57
6 68
dtype: int64
>>> (kidx + 1 + 10 * kser).sort_index()
0 11
1 22
2 33
3 44
4 55
5 66
6 77
dtype: int64Support setting to a Series via attribute access
We have added the support of setting a column via attribute assignment in DataFrame, (#1989).
>>> kdf = ks.DataFrame({'A': [1, 2, 3, None]})
>>> kdf.A = kdf.A.fillna(kdf.A.median())
>>> kdf
A
0 1.0
1 2.0
2 3.0
3 2.0Other new features, improvements and bug fixes
We added the following new features:
Series:
DataFrame
In addition, we also implement new parameters:
- Add min_count parameter for Frame.sum. (#1978)
- Added ddof parameter for GroupBy.std() and GroupBy.var() (#1994)
- Support ddof parameter for std and var. (#1986)
Along with the following fixes:
- Fix stat functions with no numeric columns. (#1967)
- Fix DataFrame.replace with NaN/None values (#1962)
- Fix cumsum and cumprod. (#1982)
- Use Python type name instead of Spark's in error messages. (#1985)
- Use object.__setattr__ in Series. (#1991)
- Adjust Series.mode to match pandas Series.mode (#1995)
- Adjust data when all the values in a column are nulls. (#2004)
- Fix as_spark_type to not support "bigint". (#2011)
Version 1.5.0
Index operations support
We improved Index operations support (#1944, #1955).
Here are some examples:
-
Before
>>> kidx = ks.Index([1, 2, 3, 4, 5]) >>> kidx + kidx Int64Index([2, 4, 6, 8, 10], dtype='int64') >>> kidx + kidx + kidx Traceback (most recent call last): ... AssertionError: args should be single DataFrame or single/multiple Series
>>> ks.Index([1, 2, 3, 4, 5]) + ks.Index([6, 7, 8, 9, 10]) Traceback (most recent call last): ... AssertionError: args should be single DataFrame or single/multiple Series
-
After
>>> kidx = ks.Index([1, 2, 3, 4, 5]) >>> kidx + kidx + kidx Int64Index([3, 6, 9, 12, 15], dtype='int64')
>>> ks.options.compute.ops_on_diff_frames = True >>> ks.Index([1, 2, 3, 4, 5]) + ks.Index([6, 7, 8, 9, 10]) Int64Index([7, 9, 13, 11, 15], dtype='int64')
Other new features and improvements
We added the following new features:
DataFrame:
Series:
Index:
to_list(#1948)
MultiIndex:
to_list(#1948)
GroupBy:
Other improvements and bug fixes
- Support DataFrame parameter in Series.dot (#1931)
- Add a best practice for checkpointing. (#1930)
- Remove implicit switch-ons of "compute.ops_on_diff_frames" (#1953)
- Fix Series._to_internal_pandas and introduce Index._to_internal_pandas. (#1952)
- Fix first/last_valid_index to support empty column DataFrame. (#1923)
- Use pandas' transpose when the data is expected to be small. (#1932)
- Fix tail to use the resolved copy (#1942)
- Avoid unneeded reset_index in DataFrameGroupBy.describe. (#1951)
- TypeError when Index.name / Series.name is not a hashable type (#1883)
- Adjust data column names before attaching default index. (#1947)
- Add plotly into the optional dependency in Koalas (#1939)
- Add plotly backend test cases (#1938)
- Don't pass stacked in plotly area chart (#1934)
- Set upperbound of matplotlib to avoid failure on Ubuntu (#1959)
- Fix GroupBy.descirbe for multi-index columns. (#1922)
- Upgrade pandas version in CI (#1961)
- Compare Series from the same anchor (#1956)
- Add videos from Data+AI Summit 2020 EUROPE. (#1963)
- Set PYARROW_IGNORE_TIMEZONE for binder. (#1965)
Version 1.4.0
Better type support
We improved the type mapping between pandas and Koalas (#1870, #1903). We added more types or string expressions to specify the data type or fixed mismatches between pandas and Koalas.
Here are some examples:
-
Added
np.float32and"float32"(matched toFloatType)>>> ks.Series([10]).astype(np.float32) 0 10.0 dtype: float32 >>> ks.Series([10]).astype("float32") 0 10.0 dtype: float32
-
Added
np.datetime64and"datetime64[ns]"(matched toTimestampType)>>> ks.Series(["2020-10-26"]).astype(np.datetime64) 0 2020-10-26 dtype: datetime64[ns] >>> ks.Series(["2020-10-26"]).astype("datetime64[ns]") 0 2020-10-26 dtype: datetime64[ns]
-
Fixed
np.intto matchLongType, notIntegerType.>>> pd.Series([100]).astype(np.int) 0 100.0 dtype: int64 >>> ks.Series([100]).astype(np.int) 0 100.0 dtype: int32 # This fixed to `int64` now.
-
Fixed
np.floatto matchDoubleType, notFloatType.>>> pd.Series([100]).astype(np.float) 0 100.0 dtype: float64 >>> ks.Series([100]).astype(np.float) 0 100.0 dtype: float32 # This fixed to `float64` now.
We also added a document which describes supported/unsupported pandas data types or data type mapping between pandas data types and PySpark data types. See: Type Support In Koalas.
Return type annotations for major Koalas objects
To improve Koala’s auto-completion in various editors and avoid misuse of APIs, we added return type annotations to major Koalas objects. These objects include DataFrame, Series, Index, GroupBy, Window objects, etc. (#1852, #1857, #1859, #1863, #1871, #1882, #1884, #1889, #1892, #1894, #1898, #1899, #1900, #1902).
The return type annotations help auto-completion libraries, such as Jedi, to infer the actual data type and provide proper suggestions:
- Before

- After

It also helps mypy enable static analysis over the method body.
pandas 1.1.4 support
We verified the behaviors of pandas 1.1.4 in Koalas.
As pandas 1.1.4 introduced a behavior change related to MultiIndex.is_monotonic (MultiIndex.is_monotonic_increasing) and MultiIndex.is_monotonic_decreasing (pandas-dev/pandas#37220), Koalas also changes the behavior (#1881).
Other new features and improvements
We added the following new features:
DataFrame:
__neg__(#1847)rename_axis(#1843)spark.repartition(#1864)spark.coalesce(#1873)spark.checkpoint(#1877)spark.local_checkpoint(#1878)reindex_like(#1880)
Series:
Index:
intersection(#1747)
MultiIndex:
intersection(#1747)
Other improvements and bug fixes
- Use SF.repeat in series.str.repeat (#1844)
- Remove warning when use cache in the context manager (#1848)
- Support a non-string name in Series' boxplot (#1849)
- Calculate fliers correctly in Series.plot.box (#1846)
- Show type name rather than type class in error messages (#1851)
- Fix DataFrame.spark.hint to reflect internal changes. (#1865)
- DataFrame.reindex supports named columns index (#1876)
- Separate InternalFrame.index_map into index_spark_column_names and index_names. (#1879)
- Fix DataFrame.xs to handle internal changes properly. (#1896)
- Explicitly disallow empty list as index_spark_colum_names and index_names. (#1895)
- Use nullable inferred schema in function apply (#1897)
- Introduce InternalFrame.index_level. (#1890)
- Remove InternalFrame.index_map. (#1901)
- Force to use the Spark's system default precision and scale when inferred data type contains DecimalType. (#1904)
- Upgrade PyArrow from 1.0.1 to 2.0.0 in CI (#1860)
- Fix read_excel to support squeeze argument. (#1905)
- Fix to_csv to avoid duplicated option 'path' for DataFrameWriter. (#1912)
Version 1.3.0
pandas 1.1 support
We verified the behaviors of pandas 1.1 in Koalas. Koalas now supports pandas 1.1 officially (#1688, #1822, #1829).
Support for non-string names
Now we support for non-string names (#1784). Previously names in Koalas, e.g., df.columns, df.colums.names, df.index.names, needed to be a string or a tuple of string, but it should allow other data types which are supported by Spark.
Before:
>>> kdf = ks.DataFrame([[1, 'x'], [2, 'y'], [3, 'z']])
>>> kdf.columns
Index(['0', '1'], dtype='object')After:
>>> kdf = ks.DataFrame([[1, 'x'], [2, 'y'], [3, 'z']])
>>> kdf.columns
Int64Index([0, 1], dtype='int64')Improve distributed-sequence default index
The performance is improved when creating a distributed-sequence as a default index type by avoiding the interaction between Python and JVM (#1699).
Standardize binary operations between int and str columns
Make behaviors of binary operations (+, -, *, /, //, %) between int and str columns consistent with respective pandas behaviors (#1828).
It standardizes binary operations as follows:
+: raiseTypeErrorbetween int column and str column (or string literal)*: act as spark SQLrepeatbetween int column(or int literal) and str columns; raiseTypeErrorif a string literal is involved-,/,//,%(modulo): raiseTypeErrorif a str column (or string literal) is involved
Other new features and improvements
We added the following new features:
DataFrame:
Series:
reindex(#1737)explode(#1777)pad(#1786)argmin(#1790)argmax(#1790)argsort(#1793)backfill(#1798)
Index:
inferred_type(#1745)item(#1744)is_unique(#1766)asi8(#1764)is_type_compatible(#1765)view(#1788)insert(#1804)
MultiIndex:
inferred_type(#1745)item(#1744)is_unique(#1766)asi8(#1764)is_type_compatible(#1765)from_frame(#1762)view(#1788)insert(#1804)
GroupBy:
get_group(#1783)
Other improvements
- Fix DataFrame.mad to work properly (#1749)
- Fix Series name after binary operations. (#1753)
- Fix GroupBy.cum~ for matching with pandas' behavior (#1708)
- Fix cumprod to work properly with Integer columns. (#1750)
- Fix DataFrame.join for MultiIndex (#1771)
- Exception handling for from_frame properly (#1791)
- Fix iloc for slice(None, 0) (#1767)
- Fix Series.__repr__ when Series.name is None. (#1796)
- DataFrame.reindex supports koalas Index parameter (#1741)
- Fix Series.fillna with inplace=True on non-nullable column. (#1809)
- Input check in various APIs (#1808, #1810, #1811, #1812, #1813, #1814, #1816, #1824)
- Fix to_list work properly in pandas==0.23 (#1823)
- Fix Series.astype to work properly (#1818)
- Frame.groupby supports dropna (#1815)
Version 1.2.0
Non-named Series support
Now we added support for non-named Series (#1712). Previously Koalas automatically named a Series "0" if no name is specified or None is set to the name, whereas pandas allows a Series without the name.
For example:
>>> ks.__version__
'1.1.0'
>>> kser = ks.Series([1, 2, 3])
>>> kser
0 1
1 2
2 3
Name: 0, dtype: int64
>>> kser.name = None
>>> kser
0 1
1 2
2 3
Name: 0, dtype: int64Now the Series will be non-named.
>>> ks.__version__
'1.2.0'
>>> ks.Series([1, 2, 3])
0 1
1 2
2 3
dtype: int64
>>> kser = ks.Series([1, 2, 3], name="a")
>>> kser.name = None
>>> kser
0 1
1 2
2 3
dtype: int64More stable "distributed-sequence" default index
Previously "distributed-sequence" default index had sometimes produced wrong values or even raised an exception. For example, the codes below:
>>> from databricks import koalas as ks
>>> ks.options.compute.default_index_type = 'distributed-sequence'
>>> ks.range(10).reset_index()did not work as below:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
...
pyspark.sql.utils.PythonException:
An exception was thrown from the Python worker. Please see the stack trace below.
Traceback (most recent call last):
...
File "/.../koalas/databricks/koalas/internal.py", line 620, in offset
current_partition_offset = sums[id.iloc[0]]
KeyError: 103
We investigated and made the default index type more stable (#1701). Now it unlikely causes such situations and it is stable enough.
Improve testing infrastructure
We changed the testing infrastructure to use pandas' testing utils for exact check (#1722). Now it compares even index/column types and names so that we will be able to follow pandas more strictly.
Other new features and improvements
We added the following new features:
DataFrame:
last_valid_index(#1705)
Series:
GroupBy:
cumcount(#1702)
Other improvements
- Refine Spark I/O. (#1667)
- Set
partitionByexplicitly into_parquet. - Add
modeandpartition_colstoto_csvandto_json. - Fix type hints to use
Optional.
- Set
- Make read_excel read from DFS if the underlying Spark is 3.0.0 or above. (#1678, #1693, #1694, #1692)
- Support callable instances to apply as a function, and fix groupby.apply to keep the index when possible (#1686)
- Bug fixing for hasnans when non-DoubleType. (#1681)
- Support axis=1 for DataFrame.dropna(). (#1689)
- Allow assining index as a column (#1696)
- Try to read pandas metadata in read_parquet if index_col is None. (#1695)
- Include pandas Index object in dataframe indexing options (#1698)
- Unified
PlotAccessorfor DataFrame and Series (#1662) - Fix SeriesGroupBy.nsmallest/nlargest. (#1713)
- Fix DataFrame.size to consider its number of columns. (#1715)
- Fix first_valid_index() for Empty object (#1704)
- Fix index name when groupby.apply returns a single row. (#1719)
- Support subtraction of date/timestamp with literals. (#1721)
- DataFrame.reindex(fill_value) does not fill existing NaN values (#1723)
Version 1.1.0
API extensions
We added support for API extensions (#1617).
You can register your custom accessors to DataFrame, Seires, and Index.
For example, in your library code:
from databricks.koalas.extensions import register_dataframe_accessor
@register_dataframe_accessor("geo")
class GeoAccessor:
def __init__(self, koalas_obj):
self._obj = koalas_obj
# other constructor logic
@property
def center(self):
# return the geographic center point of this DataFrame
lat = self._obj.latitude
lon = self._obj.longitude
return (float(lon.mean()), float(lat.mean()))
def plot(self):
# plot this array's data on a map
pass
...Then, in a session:
>>> from my_ext_lib import GeoAccessor
>>> kdf = ks.DataFrame({"longitude": np.linspace(0,10),
... "latitude": np.linspace(0, 20)})
>>> kdf.geo.center
(5.0, 10.0)
>>> kdf.geo.plot()
...See also: https://koalas.readthedocs.io/en/latest/reference/extensions.html
Plotting backend
We introduced plotting.backend configuration (#1639).
Plotly (>=4.8) or other libraries that pandas supports can be used as a plotting backend if they are installed in the environment.
>>> kdf = ks.DataFrame([[1, 2, 3, 4], [5, 6, 7, 8]], columns=["A", "B", "C", "D"])
>>> kdf.plot(title="Example Figure") # defaults to backend="matplotlib"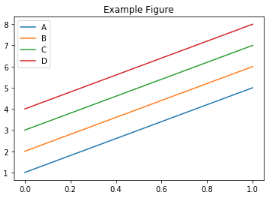
>>> fig = kdf.plot(backend="plotly", title="Example Figure", height=500, width=500)
>>> ## same as:
>>> # ks.options.plotting.backend = "plotly"
>>> # fig = kdf.plot(title="Example Figure", height=500, width=500)
>>> fig.show()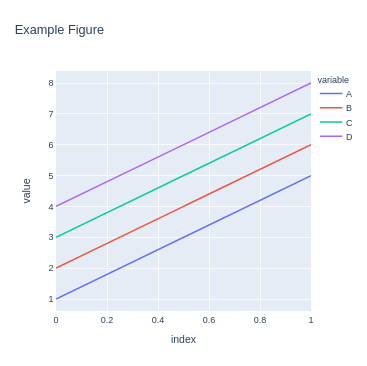
Each backend returns the figure in their own format, allowing for further editing or customization if required.
>>> fig.update_layout(template="plotly_dark")
>>> fig.show()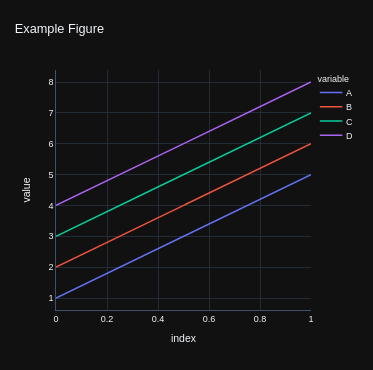
Koalas accessor
We introduced koalas accessor and some methods specific to Koalas (#1613, #1628).
DataFrame.apply_batch, DataFrame.transform_batch, and Series.transform_batch are deprecated and moved to koalas accessor.
>>> kdf = ks.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
>>> def pandas_plus(pdf):
... return pdf + 1 # should always return the same length as input.
...
>>> kdf.koalas.transform_batch(pandas_plus)
a b
0 2 5
1 3 6
2 4 7>>> kdf = ks.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
>>> def pandas_filter(pdf):
... return pdf[pdf.a > 1] # allow arbitrary length
...
>>> kdf.koalas.apply_batch(pandas_filter)
a b
1 2 5
2 3 6or
>>> kdf = ks.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
>>> def pandas_plus(pser):
... return pser + 1 # should always return the same length as input.
...
>>> kdf.a.koalas.transform_batch(pandas_plus)
0 2
1 3
2 4
Name: a, dtype: int64See also: https://koalas.readthedocs.io/en/latest/user_guide/transform_apply.html
Other new features and improvements
We added the following new features:
DataFrame:
Series:
Other improvements
- Simplify Series.to_frame. (#1624)
- Make Window functions create a new DataFrame. (#1623)
- Fix Series._with_new_scol to use alias. (#1634)
- Refine concat to handle the same anchor DataFrames properly. (#1627)
- Add sort parameter to concat. (#1636)
- Enable to assign list. (#1644)
- Use SPARK_INDEX_NAME_FORMAT in combine_frames to avoid ambiguity. (#1650)
- Rename spark columns only when index=False. (#1649)
- read_csv: Implement reading of number of rows (#1656)
- Fixed ks.Index.to_series() to work properly with name paramter (#1643)
- Fix fillna to handle "ffill" and "bfill" properly. (#1654)