3.3.3. Data Dictionary Editor
This is the Working Files' editor for Data Dictionaries (DDs).
The DD Editor can be used for editing DDs. Different than other semantic documents that have a more rigid template to be followed, DDs can be documents in any way their authors want, we everything that is documents being contained in one sheet, or multiple sheets, and with different notes being used. From a semantic point of view, the main purpose of the DD editor is to help help the SDD editing by identifying the following:
- the sheet/column that has the list of labels of the file
- the sheet/column that has the description of the content within each label
On the “Data Dictionary” sheet, right click and select appropriately “Header” or “Description” based on the proper column. See the sheet name and the column name appear in the proper text boxes located at the top of the page.

When the selection of header and description columns is completed, click the “Add to SDD” to arrive at the “Add File Headers into SDD” page.
Here, select the SDD file to receiving the DD information (be sure to select an empty SDD file)

After completion, click the “Back to SDD” button and arrive at the appropriate SDD editor page. Here, navigate to the “Dictionary Mapping sheet
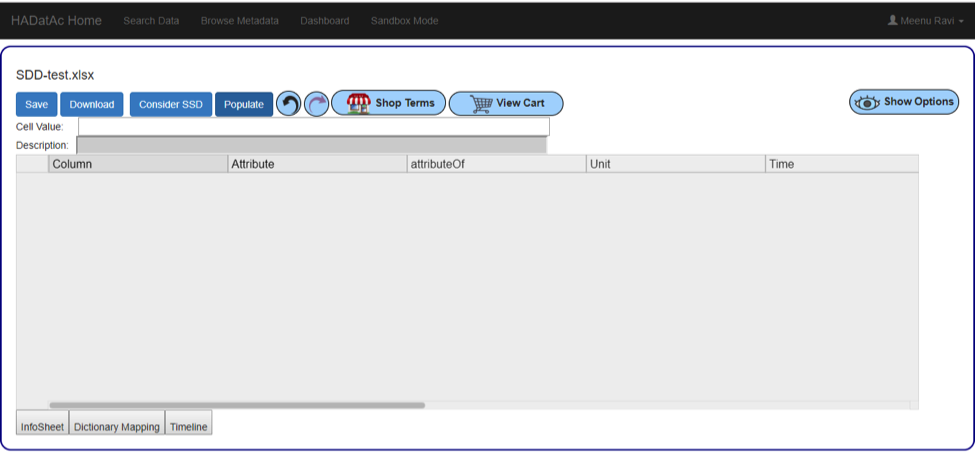
To fill in the empty sheet, click the “Populate’ button for the column headers from the DD to automatically populate the SDD.

Finally, continue to edit the SDD by editing values and shopping for terms. More info about this can be found in Section 3.3.2.
-
Installation
1.1. Installing for Linux (Production)
1.2. Installing for Linux (Development)
1.3. Installing for MacOS (Development)
1.4. Deploying with Docker (Production)
1.5. Deploying with Docker (Development)
1.6. Installing for Vagrant under Windows
1.7. Upgrading
1.8. Starting HADatAc
1.9. Stopping HADatAc -
Setting Up
2.1. Software Configuration
2.2. Knowledge Graph Bootstrap
2.2.1. Knowledge Graph
2.2.2. Bootstrap without Labkey
2.2.3. Bootstrap with Labkey
2.3. Config Verification -
Using HADatAc
3.1. Initial Page
3.1.1. Home Button
3.1.2. Sandbox Mode Button
3.2. File Ingestion
3.2.1. Ingesting Study Content
3.2.2. Manual Submission of Files
3.2.3. Automatic Submission of Files
3.2.4. Data File Operations
3.3. Manage Working Files 3.3.1. [Create Empty Semantic File from Template]
3.3.2. SDD Editor
3.3.3. DD Editor
3.4. Manage Metadata
3.4.1. Manage Instrument Infrastructure
3.4.2. Manage Deployments 3.4.3. Manage Studies
3.4.4. [Manage Object Collections]
3.4.5. Manage Streams
3.4.6. Manage Semantic Data Dictionaries
3.4.7. Manage Indicators
3.5. Data Search
3.5.1. Data Faceted Search
3.5.2. Data Spatial Search
3.6. Metadata Browser and Search
3.7. Knowledge Graph Browser
3.8. API
3.9. Data Download -
Software Architecture
4.1. Software Components
4.2. The Human-Aware Science Ontology (HAScO) -
Metadata Files
5.1. Deployment Specification (DPL)
5.2. Study Specification (STD)
5.3. Semantic Study Design (SSD)
5.4. Semantic Data Dictionary (SDD)
5.5. Stream Specification (STR) -
Content Evolution
6.1. Namespace List Update
6.2. Ontology Update
6.3. [DPL Update]
6.4. [SSD Update]
6.5. SDD Update -
Data Governance
7.1. Access Network
7.2. User Status, Categories and Access Permissions
7.3. Data and Metadata Privacy - HADatAc-Supported Projects
- Derived Products and Technologies
- Glossary